publications
Publications are sorted in reverse chronological order and grouped by type.
2026
journal articles
- RA-L
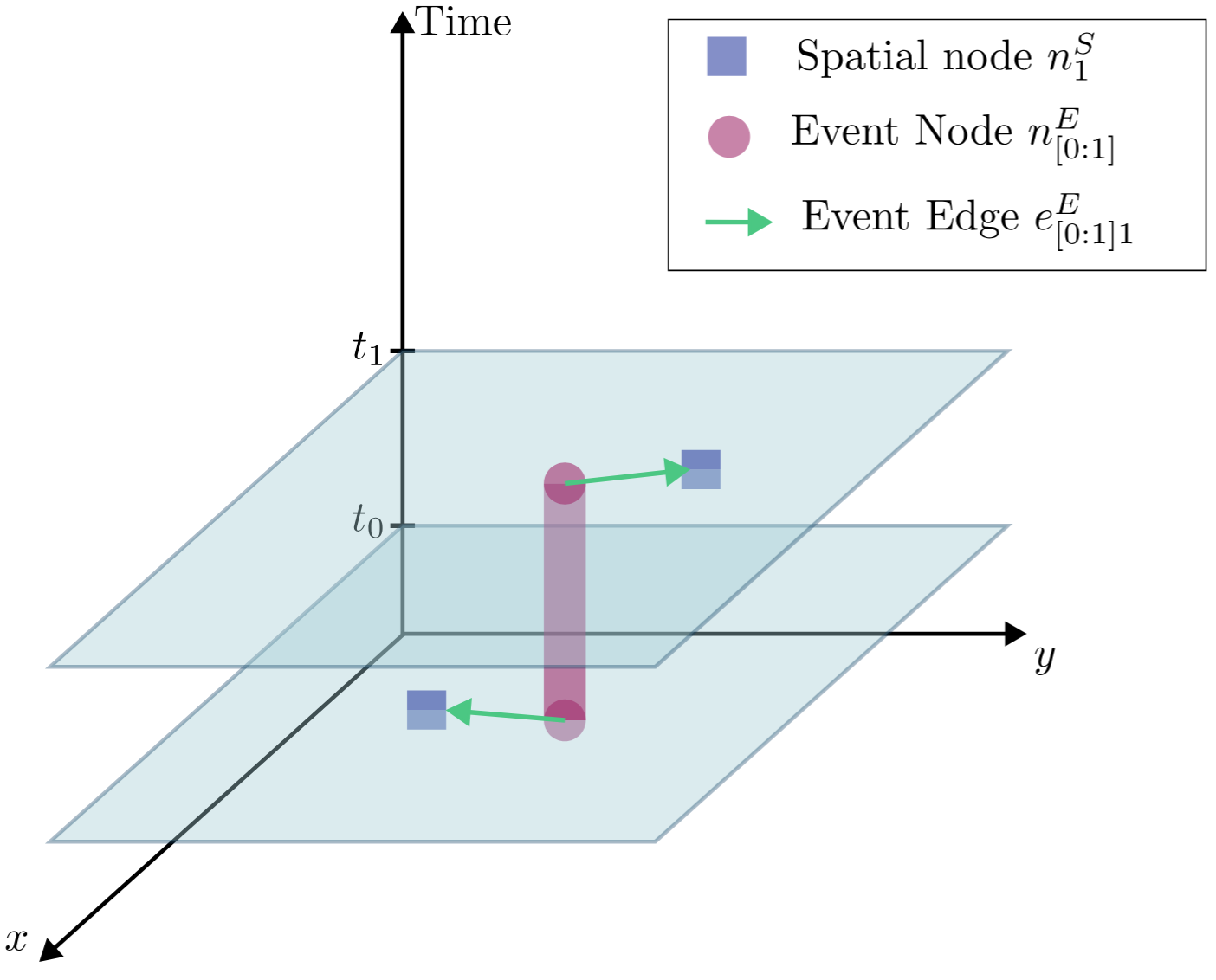 Event-Grounding Graph: Unified Spatio-Temporal Scene Graph from Robotic ObservationsPhuoc Nguyen, Francesco Verdoja, and Ville KyrkiIEEE Robotics and Automation Letters, May 2026
Event-Grounding Graph: Unified Spatio-Temporal Scene Graph from Robotic ObservationsPhuoc Nguyen, Francesco Verdoja, and Ville KyrkiIEEE Robotics and Automation Letters, May 2026A fundamental aspect for building intelligent autonomous robots that can assist humans in their daily lives is the construction of rich environmental representations. While advances in semantic scene representations have enriched robotic scene understanding, current approaches lack a connection between spatial features and dynamic events; e.g., connecting the blue mug to the event washing a mug. In this work, we introduce the event-grounding graph (EGG), a framework grounding event interactions to spatial features of a scene. This representation allows robots to perceive, reason, and respond to complex spatio-temporal queries. Experiments using real robotic data demonstrate EGG’s capability to retrieve relevant information and respond accurately to human inquiries concerning the environment and events within.
@article{202605_nguyen_event-grounding, title = {Event-{Grounding} {Graph}: {Unified} {Spatio}-{Temporal} {Scene} {Graph} from {Robotic} {Observations}}, shorttitle = {Event-{Grounding} {Graph}}, volume = {11}, doi = {10.1109/LRA.2026.3669042}, number = {5}, journal = {IEEE Robotics and Automation Letters}, publisher = {IEEE}, author = {Nguyen, Phuoc and Verdoja, Francesco and Kyrki, Ville}, month = may, year = {2026}, pages = {5286--5293}, } - DAI
 Enablers and barriers to AI adoption: evidence from the heavy machinery industryAlena Valtonen, Kirsi Kokkonen, Minna Saunila, Francesco Verdoja, Grzegorz Orzechowski, and 3 more authorsDiscover Artificial Intelligence, Feb 2026
Enablers and barriers to AI adoption: evidence from the heavy machinery industryAlena Valtonen, Kirsi Kokkonen, Minna Saunila, Francesco Verdoja, Grzegorz Orzechowski, and 3 more authorsDiscover Artificial Intelligence, Feb 2026Artificial intelligence (AI) holds significant potential for heavy machinery manufacturing, yet adoption in this safety–critical and highly customized industry remains limited and insufficiently understood. This study examines enablers and barriers to AI adoption through a multiple-case study of heavy machinery manufacturers, analyzing dynamics across external, organizational, and individual levels. The findings show that AI adoption is shaped less by technological maturity than by safety requirements, regulatory complexity, organizational capabilities, and human expertise. Safety emerges as a central lens guiding adoption decisions across all levels. Simulation plays a key enabling role by supporting safe development, validation, training, and coordination, while reducing uncertainty about AI reliability. Adoption follows a hybrid and incremental logic, with firms retaining humans in the loop and expanding AI-supported decision-making as reliability and confidence increase. Organizational orchestration capability is critical for aligning technological possibilities with regulatory, organizational, and human constraints. By focusing on heavy machinery manufacturing, this study extends AI adoption research to an underexplored industrial context and clarifies how enablers and barriers shape AI adoption pathways.
@article{202602_valtonen_enablers, title = {Enablers and barriers to {AI} adoption: evidence from the heavy machinery industry}, shorttitle = {Enablers and barriers to {AI} adoption}, todo_volume = {xx}, doi = {10.1007/s44163-026-01038-0}, todo_number = {xx}, journal = {Discover Artificial Intelligence}, publisher = {Springer}, author = {Valtonen, Alena and Kokkonen, Kirsi and Saunila, Minna and Verdoja, Francesco and Orzechowski, Grzegorz and Kurvinen, Emil and Aaltonen, Päivi and Salakka, Jussi}, month = feb, year = {2026}, todo_pages = {xx--xx}, }
conference articles
- ICRA
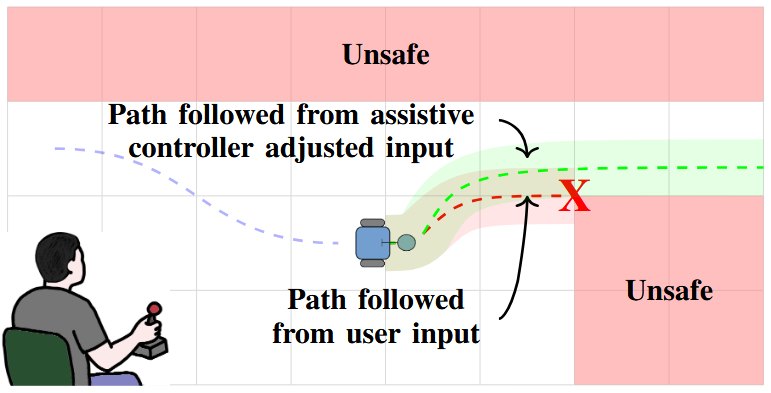 Minimal Intervention Shared Control with Guaranteed Safety under Non-Convex ConstraintsShivam Chaubey, Francesco Verdoja, Shankar Deka, and Ville KyrkiIn 2026 IEEE Int. Conf. on Robotics and Automation (ICRA), Jun 2026
Minimal Intervention Shared Control with Guaranteed Safety under Non-Convex ConstraintsShivam Chaubey, Francesco Verdoja, Shankar Deka, and Ville KyrkiIn 2026 IEEE Int. Conf. on Robotics and Automation (ICRA), Jun 2026Shared control combines human intention with autonomous decision-making, from low-level safety overrides to high-level task guidance, enabling systems that adapt to users while ensuring safety and performance. This enhances task effectiveness and user experience across domains such as assistive robotics, teleoperation, and autonomous driving. However, existing shared control methods, based on e.g. Model Predictive Control, Control Barrier Functions, or learning-based control, struggle with feasibility, scalability, or safety guarantees, particularly since the user input is unpredictable. To address these challenges, we propose an assistive controller framework based on Constrained Optimal Control Problem that incorporates an offline-computed Control Invariant Set, enabling online computation of control actions that ensure feasibility, strict constraint satisfaction, and minimal override of user intent. Moreover, the framework can accommodate structured class of non-convex constraints, which are common in real-world scenarios. We validate the approach through a large-scale user study with 66 participants–one of the most extensive in shared control research–using a computer game environment to assess task load, trust, and perceived control, in addition to performance. The results show consistent improvements across all these aspects without compromising safety and user intent.
@inproceedings{202606_chaubey_misc, address = {Vienna, Austria}, title = {{Minimal} {Intervention} {Shared} {Control} with {Guaranteed} {Safety} under {Non}-{Convex} {Constraints}}, booktitle = {2026 {IEEE} {Int.} {Conf.} on {Robotics} and {Automation} ({ICRA})}, publisher = {IEEE}, author = {Chaubey, Shivam and Verdoja, Francesco and Deka, Shankar and Kyrki, Ville}, url = {https://arxiv.org/abs/2507.02438}, month = jun, year = {2026}, } - ICRA
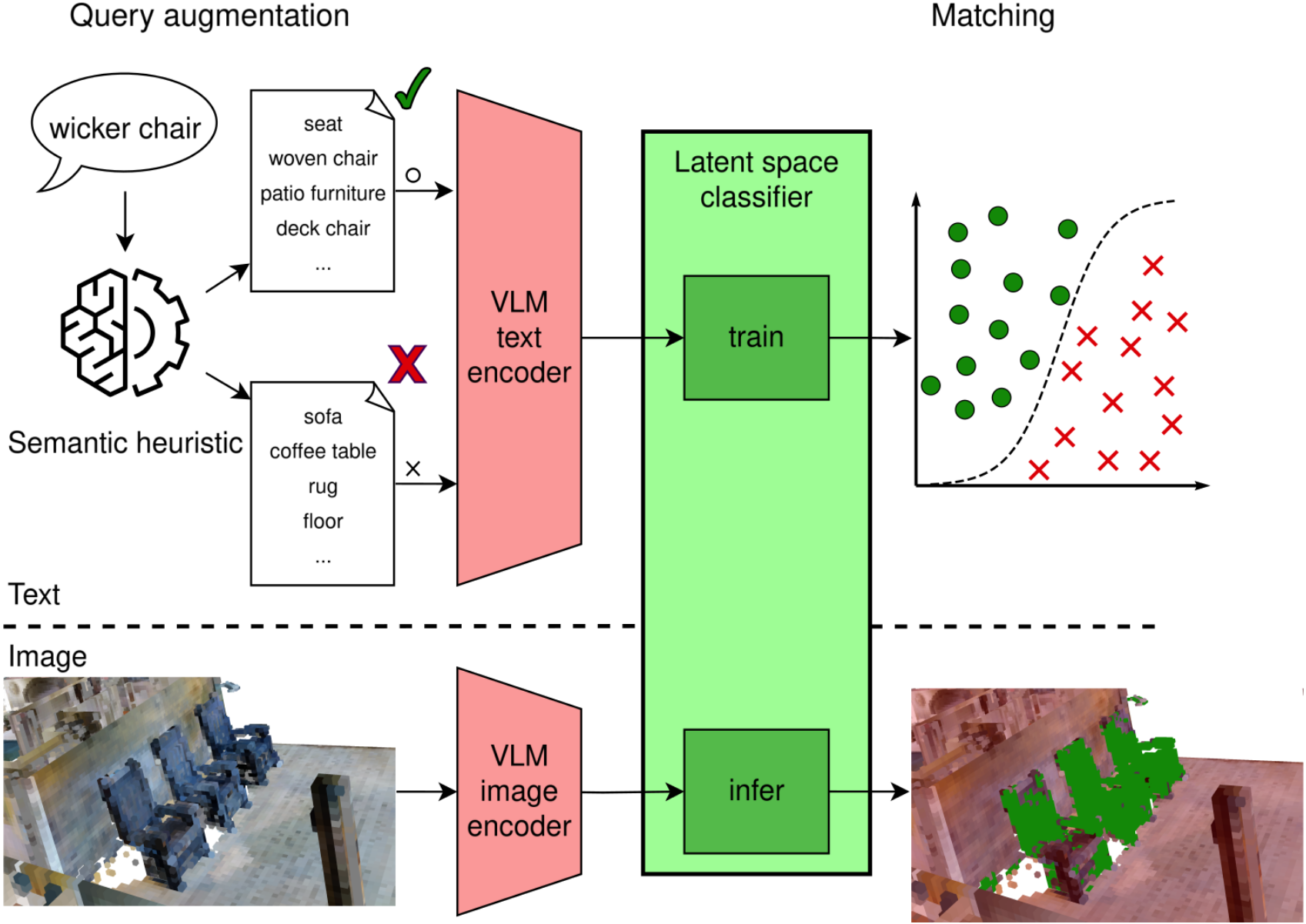 QuASH: Using Natural-Language Heuristics to Query Visual-Language Robotic MapsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiIn 2026 IEEE Int. Conf. on Robotics and Automation (ICRA), Jun 2026
QuASH: Using Natural-Language Heuristics to Query Visual-Language Robotic MapsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiIn 2026 IEEE Int. Conf. on Robotics and Automation (ICRA), Jun 2026Embeddings from Visual-Language Models are increasingly utilized to represent semantics in robotic maps, offering an open-vocabulary scene understanding that surpasses traditional, limited labels. Embeddings enable on-demand querying by comparing embedded user text prompts to map embeddings via a similarity metric. The key challenge in performing the task indicated in a query is that the robot must determine the parts of the environment relevant to the query. This paper proposes a solution to this challenge. We leverage natural-language synonyms and antonyms associated with the query within the embedding space, applying heuristics to estimate the language space relevant to the query, and use that to train a classifier to partition the environment into matches and non-matches. We evaluate our method through extensive experiments, querying both maps and standard image benchmarks. The results demonstrate increased queryability of maps and images. Our querying technique is agnostic to the representation and encoder used, and requires limited training.
@inproceedings{202606_pekkanen_quash, address = {Vienna, Austria}, title = {{QuASH}: {Using} {Natural}-{Language} {Heuristics} to {Query} {Visual}-{Language} {Robotic} {Maps}}, shorttitle = {{QuASH}}, booktitle = {2026 {IEEE} {Int.} {Conf.} on {Robotics} and {Automation} ({ICRA})}, publisher = {IEEE}, author = {Pekkanen, Matti and Verdoja, Francesco and Kyrki, Ville}, url = {http://arxiv.org/abs/2510.14546}, month = jun, year = {2026}, }
preprints
- IROS
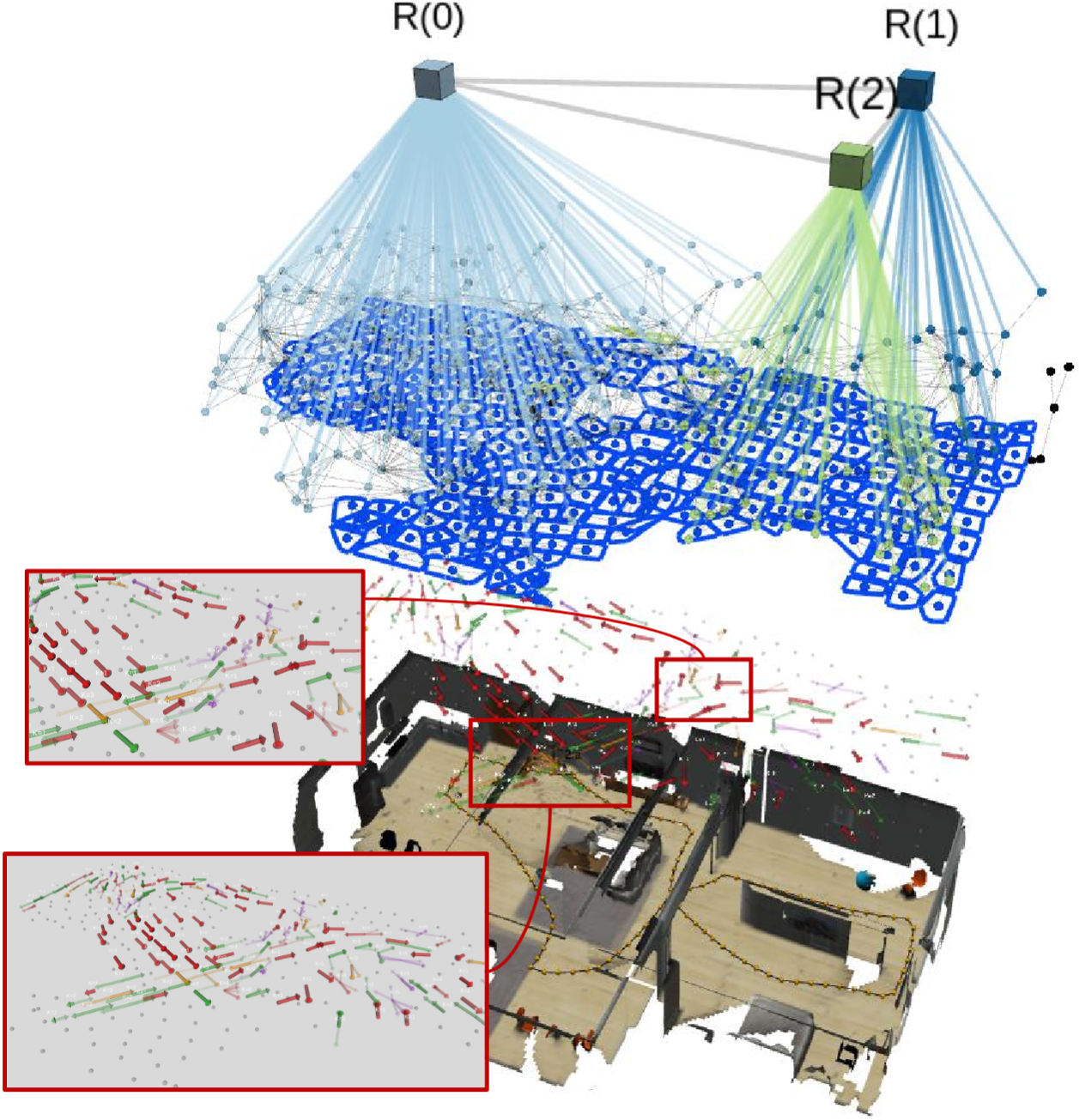 Rheos: Modelling Continuous Motion Dynamics in Hierarchical 3D Scene GraphsIacopo Catalano, Francesco Verdoja, Javier Civera, Jorge Peña-Queralta, and Julio A. PlacedMar 20262026 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS) (submitted)
Rheos: Modelling Continuous Motion Dynamics in Hierarchical 3D Scene GraphsIacopo Catalano, Francesco Verdoja, Javier Civera, Jorge Peña-Queralta, and Julio A. PlacedMar 20262026 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS) (submitted)3D Scene Graphs (3DSGs) provide hierarchical, multi-resolution abstractions that encode the geometric and semantic structure of an environment, yet their treatment of dynamics remains limited to tracking individual agents. Maps of Dynamics (MoDs) complement this by modeling aggregate motion patterns, but rely on uniform grid discretizations that lack semantic grounding and scale poorly. We present Rheos, a framework that explicitly embeds continuous directional motion models into an additional dynamics layer of a hierarchical 3DSG that enhances the navigational properties of the graph. Each dynamics node maintains a semi-wrapped Gaussian mixture model that captures multimodal directional flow as a principled probability distribution with explicit uncertainty, replacing the discrete histograms used in prior work. To enable online operation, Rheos employs reservoir sampling for bounded-memory observation buffers, parallel per-cell model updates and a principled Bayesian Information Criterion (BIC) sweep that selects the optimal number of mixture components, reducing per-update initialization cost from quadratic to linear in the number of samples. Evaluated across four spatial resolutions in a simulated pedestrian environment, Rheos consistently outperforms the discrete baseline under continuous as well as unfavorable discrete metrics. We release our implementation as open source.
@misc{202603_catalano_rheos, title = {Rheos: {Modelling} {Continuous} {Motion} {Dynamics} in {Hierarchical} {3D} {Scene} {Graphs}}, shorttitle = {Rheos}, author = {Catalano, Iacopo and Verdoja, Francesco and Civera, Javier and Peña-Queralta, Jorge and Placed, Julio A.}, url = {http://arxiv.org/abs/2603.20239}, month = mar, year = {2026}, publisher = {arXiv}, note = {2026 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS}) (submitted)} } - RO-MAN
 Relational Scene Graphs for Object Grounding of Natural Language CommandsJulia Kuhn, Francesco Verdoja, Tsvetomila Mihaylova, and Ville KyrkiMar 20262026 IEEE IEEE Int. Conf. on Robot and Human Interactive Communication (RO-MAN) (submitted)
Relational Scene Graphs for Object Grounding of Natural Language CommandsJulia Kuhn, Francesco Verdoja, Tsvetomila Mihaylova, and Ville KyrkiMar 20262026 IEEE IEEE Int. Conf. on Robot and Human Interactive Communication (RO-MAN) (submitted)Robots are finding wider adoption in human environments, increasing the need for natural human-robot interaction. However, understanding a natural language command requires the robot to infer the intended task and how to decompose it into executable actions, and to ground those actions in the robot’s knowledge of the environment, including relevant objects, agents, and locations. This challenge can be addressed by combining the capabilities of Large language models (LLMs) to understand natural language with 3D scene graphs (3DSGs) for grounding inferred actions in a semantic representation of the environment. However, many 3DSGs lack explicit spatial relations between objects, even though humans often rely on these relations to describe an environment. This paper investigates whether incorporating open- or closed-vocabulary spatial relations into 3DSGs can improve the ability of LLMs to interpret natural language commands. To address this, we propose an LLM-based pipeline for target object grounding from open-vocabulary language commands and a vision language model (VLM)-based pipeline to add open-vocabulary spatial edges to 3DSGs from images captured while mapping. Finally, two LLMs are evaluated in a study assessing their performance on the downstream task of target object grounding. Our study demonstrates that explicit spatial relations improve the ability of LLMs to ground objects. Moreover, open-vocabulary relation generation with VLMs proves feasible from robot-captured images, but their advantage over closed-vocabulary relations is found to be limited.
@misc{202603_kuhn_relational, title = {Relational {Scene} {Graphs} for {Object} {Grounding} of {Natural} {Language} {Commands}}, author = {Kuhn, Julia and Verdoja, Francesco and Mihaylova, Tsvetomila and Kyrki, Ville}, url = {http://arxiv.org/abs/2602.04635}, month = mar, year = {2026}, publisher = {arXiv}, note = {2026 IEEE {IEEE} {Int.}\ {Conf.}\ on {Robot} and {Human} {Interactive} {Communication} ({RO}-{MAN}) (submitted)} } - AIM
 ReMoBot: Retrieval-Based Few-Shot Imitation Learning for Mobile Manipulation with Vision Foundation ModelsYuying Zhang, Wenyan Yang, Francesco Verdoja, Ville Kyrki, and Joni PajarinenFeb 20262026 IEEE/ASME Int. Conf. on Advanced Intelligent Mechatronics (AIM) (submitted)
ReMoBot: Retrieval-Based Few-Shot Imitation Learning for Mobile Manipulation with Vision Foundation ModelsYuying Zhang, Wenyan Yang, Francesco Verdoja, Ville Kyrki, and Joni PajarinenFeb 20262026 IEEE/ASME Int. Conf. on Advanced Intelligent Mechatronics (AIM) (submitted)Imitation learning (IL) algorithms typically distill experience into parametric behavior policies to mimic expert demonstrations. However, with limited demonstrations, existing methods often struggle to generate accurate actions, particularly under partial observability. To address this problem, we introduce a few-shot IL approach, ReMoBot, which directly retrieves information from demonstrations to solve Mobile manipulation tasks with ego-centric visual observations. Given the current observation, ReMoBot utilizes vision foundation models to identify relevant demonstrations, considering visual similarity w.r.t. both individual observations and history trajectories. A motion selection policy then selects the proper command for the robot until the task is successfully completed. The performance of ReMoBot is evaluated on three mobile manipulation tasks with a Boston Dynamics Spot robot in both simulation and the real world. After benchmarking five approaches in simulation, we compare our method with two baselines in the real world, training directly on the real-world dataset without sim-to-real transfer. With only 20 demonstrations, ReMoBot outperforms the baselines, achieving high success rates in Table Uncover (70%) and Gap Cover (80%), while also showing promising performance on the more challenging Curtain Open task in the real-world setting. Furthermore, ReMoBot demonstrates generalization across varying robot positions, object sizes, and material types.
@misc{202602_zhang_remobot, title = {{ReMoBot}: {Retrieval}-{Based} {Few}-{Shot} {Imitation} {Learning} for {Mobile} {Manipulation} with {Vision} {Foundation} {Models}}, shorttitle = {{ReMoBot}}, author = {Zhang, Yuying and Yang, Wenyan and Verdoja, Francesco and Kyrki, Ville and Pajarinen, Joni}, url = {http://arxiv.org/abs/2408.15919}, month = feb, year = {2026}, publisher = {arXiv}, note = {2026 {IEEE/ASME} {Int.}\ {Conf.}\ on {Advanced} {Intelligent} {Mechatronics} (AIM) (submitted)} }
2025
conference articles
- IROS
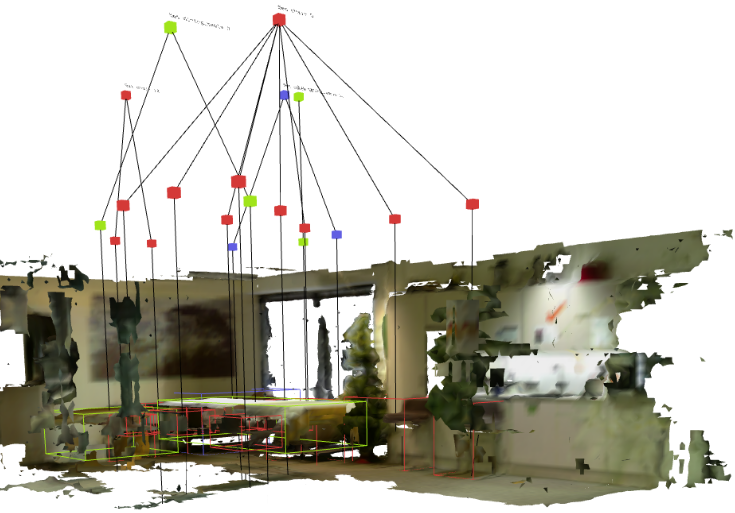 REACT: Real-time Efficient Attribute Clustering and Transfer for Updatable 3D Scene GraphPhuoc Nguyen, Francesco Verdoja, and Ville KyrkiIn 2025 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2025
REACT: Real-time Efficient Attribute Clustering and Transfer for Updatable 3D Scene GraphPhuoc Nguyen, Francesco Verdoja, and Ville KyrkiIn 2025 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2025Modern-day autonomous robots need high-level map representations to perform sophisticated tasks. Recently, 3D scene graphs (3DSGs) have emerged as a promising alternative to traditional grid maps, blending efficient memory use and rich feature representation. However, most efforts to apply them have been limited to static worlds. This work introduces REACT, a framework that efficiently performs real-time attribute clustering and transfer to relocalize object nodes in a 3DSG. REACT employs a novel method for comparing object instances using an embedding model trained on triplet loss, facilitating instance clustering and matching. Experimental results demonstrate that REACT is able to relocalize objects while maintaining computational efficiency. The REACT framework’s source code will be available as an open-source project, promoting further advancements in reusable and updatable 3DSGs.
@inproceedings{202510_nguyen_react, address = {Hangzhou, China}, title = {{REACT}: {Real}-time {Efficient} {Attribute} {Clustering} and {Transfer} for {Updatable} {3D} {Scene} {Graph}}, shorttitle = {{REACT}}, doi = {10.1109/IROS60139.2025.11247273}, booktitle = {2025 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Nguyen, Phuoc and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2025}, pages = {2209--2216}, } - IROS
 Do Visual-Language Grid Maps Capture Latent Semantics?Matti Pekkanen, Tsvetomila Mihaylova, Francesco Verdoja, and Ville KyrkiIn 2025 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2025
Do Visual-Language Grid Maps Capture Latent Semantics?Matti Pekkanen, Tsvetomila Mihaylova, Francesco Verdoja, and Ville KyrkiIn 2025 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2025Visual-language models (VLMs) have recently been introduced in robotic mapping using the latent representations, i.e., embeddings, of the VLMs to represent semantics in the map. They allow moving from a limited set of human-created labels toward open-vocabulary scene understanding, which is very useful for robots when operating in complex real-world environments and interacting with humans. While there is anecdotal evidence that maps built this way support downstream tasks, such as navigation, rigorous analysis of the quality of the maps using these embeddings is missing. In this paper, we propose a way to analyze the quality of maps created using VLMs. We investigate two critical properties of map quality: queryability and distinctness. The evaluation of queryability addresses the ability to retrieve information from the embeddings. We investigate intra-map distinctness to study the ability of the embeddings to represent abstract semantic classes and inter-map distinctness to evaluate the generalization properties of the representation. We propose metrics to evaluate these properties and evaluate two state-of-the-art mapping methods, VLMaps and OpenScene, using two encoders, LSeg and OpenSeg, using real-world data from the Matterport3D data set. Our findings show that while 3D features improve queryability, they are not scale invariant, whereas image-based embeddings generalize to multiple map resolutions. This allows the image-based methods to maintain smaller map sizes, which can be crucial for using these methods in real-world deployments. Furthermore, we show that the choice of the encoder has an effect on the results. The results imply that properly thresholding open-vocabulary queries is an open problem.
@inproceedings{202510_pekkanen_visual-language, address = {Hangzhou, China}, title = {Do {Visual}-{Language} {Grid} {Maps} {Capture} {Latent} {Semantics}?}, doi = {10.1109/IROS60139.2025.11247447}, booktitle = {2025 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Pekkanen, Matti and Mihaylova, Tsvetomila and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2025}, pages = {4059--4066}, }
workshop articles
- CoRL
 ReMoBot: Retrieval-Based Few-Shot Imitation Learning for Mobile Manipulation with Vision Foundation ModelsYuying Zhang, Wenyan Yang, Francesco Verdoja, Ville Kyrki, and Joni PajarinenSep 2025Presented at the “RemembeRL” workshop at the 2025 Conference on Robot Learning (CoRL)
ReMoBot: Retrieval-Based Few-Shot Imitation Learning for Mobile Manipulation with Vision Foundation ModelsYuying Zhang, Wenyan Yang, Francesco Verdoja, Ville Kyrki, and Joni PajarinenSep 2025Presented at the “RemembeRL” workshop at the 2025 Conference on Robot Learning (CoRL)Imitation learning (IL) algorithms typically distill experience into parametric behavior policies to mimic expert demonstrations. However, with limited demonstrations, existing methods often struggle to generate accurate actions, particularly under partial observability. To address this problem, we introduce a few-shot IL approach, ReMoBot, which directly retrieves information from demonstrations to solve Mobile manipulation tasks with ego-centric visual observations. Given the current observation, ReMoBot utilizes vision foundation models to identify relevant demonstrations, considering visual similarity w.r.t. both individual observations and history trajectories. A motion selection policy then selects the proper command for the robot until the task is successfully completed. The performance of ReMoBot is evaluated on three mobile manipulation tasks with a Boston Dynamics Spot robot in both simulation and the real world. After benchmarking five approaches in simulation, we compare our method with two baselines in the real world, training directly on the real-world dataset without sim-to-real transfer. With only 20 demonstrations, ReMoBot outperforms the baselines, achieving high success rates in Table Uncover (70%) and Gap Cover (80%), while also showing promising performance on the more challenging Curtain Open task in the real-world setting. Furthermore, ReMoBot demonstrates generalization across varying robot positions, object sizes, and material types.
@online{202509_zhang_remobot_corl, title = {{ReMoBot}: {Retrieval}-{Based} {Few}-{Shot} {Imitation} {Learning} for {Mobile} {Manipulation} with {Vision} {Foundation} {Models}}, shorttitle = {{ReMoBot}}, author = {Zhang, Yuying and Yang, Wenyan and Verdoja, Francesco and Kyrki, Ville and Pajarinen, Joni}, url = {https://rememberl-corl25.github.io}, month = sep, year = {2025}, note = {Presented at the ``RemembeRL'' workshop at the 2025 Conference on Robot Learning (CoRL)} }
preprints
- RA-L
 MoDeSuite: Robot Learning Task Suite for Benchmarking Mobile Manipulation with Deformable ObjectsYuying Zhang, Kevin Sebastian Luck, Francesco Verdoja, Ville Kyrki, and Joni PajarinenJul 2025IEEE Robotics and Automation Letters (submitted)
MoDeSuite: Robot Learning Task Suite for Benchmarking Mobile Manipulation with Deformable ObjectsYuying Zhang, Kevin Sebastian Luck, Francesco Verdoja, Ville Kyrki, and Joni PajarinenJul 2025IEEE Robotics and Automation Letters (submitted)Mobile manipulation is a critical capability for robots operating in diverse, real-world environments. However, manipulating deformable objects and materials remains a major challenge for existing robot learning algorithms. While various benchmarks have been proposed to evaluate manipulation strategies with rigid objects, there is still a notable lack of standardized benchmarks that address mobile manipulation tasks involving deformable objects. To address this gap, we introduce MoDeSuite, the first Mobile Manipulation Deformable Object task suite, designed specifically for robot learning. MoDeSuite consists of eight distinct mobile manipulation tasks covering both elastic objects and deformable objects, each presenting a unique challenge inspired by real-world robot applications. Success in these tasks requires effective collaboration between the robot’s base and manipulator, as well as the ability to exploit the deformability of the objects. To evaluate and demonstrate the use of the proposed benchmark, we train two state-of-the-art reinforcement learning algorithms and two imitation learning algorithms, highlighting the difficulties encountered and showing their performance in simulation. Furthermore, we demonstrate the practical relevance of the suite by deploying the trained policies directly into the real world with the Spot robot, showcasing the potential for sim-to-real transfer. We expect that MoDeSuite will open a novel research domain in mobile manipulation involving deformable objects.
@misc{202507_zhang_modesuite, title = {{MoDeSuite}: Robot Learning Task Suite for Benchmarking Mobile Manipulation with Deformable Objects}, shorttitle = {{MoDeSuite}}, author = {Zhang, Yuying and Luck, Kevin Sebastian and Verdoja, Francesco and Kyrki, Ville and Pajarinen, Joni}, url = {https://arxiv.org/abs/2507.21796}, month = jul, year = {2025}, publisher = {arXiv}, note = {IEEE Robotics and Automation Letters (submitted)} }
2024
conference articles
- IROS
 Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory GenerationShivam Chaubey, Francesco Verdoja, and Ville KyrkiIn 2024 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2024
Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory GenerationShivam Chaubey, Francesco Verdoja, and Ville KyrkiIn 2024 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2024Nominated for the Best Safety, Security, and Rescue Robotics Paper award sponsored by the International Rescue System Initiative (IRSI) at the 2024 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)
Learning from Demonstration allows robots to mimic human actions. However, these methods do not model constraints crucial to ensure safety of the learned skill. Moreover, even when explicitly modelling constraints, they rely on the assumption of a known cost function, which limits their practical usability for task with unknown cost. In this work we propose a two-step optimization process that allow to estimate cost and constraints by decoupling the learning of cost functions from the identification of unknown constraints within the demonstrated trajectories. Initially, we identify the cost function by isolating the effect of constraints on parts of the demonstrations. Subsequently, a constraint leaning method is used to identify the unknown constraints. Our approach is validated both on simulated trajectories and a real robotic manipulation task. Our experiments show the impact that incorrect cost estimation has on the learned constraints and illustrate how the proposed method is able to infer unknown constraints, such as obstacles, from demonstrated trajectories without any initial knowledge of the cost.
@inproceedings{202410_chaubey_jointly, address = {Abu Dhabi, UAE}, title = {Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory Generation}, doi = {10.1109/IROS58592.2024.10802533}, booktitle = {2024 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Chaubey, Shivam and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2024}, pages = {3635--3642}, } - IROS
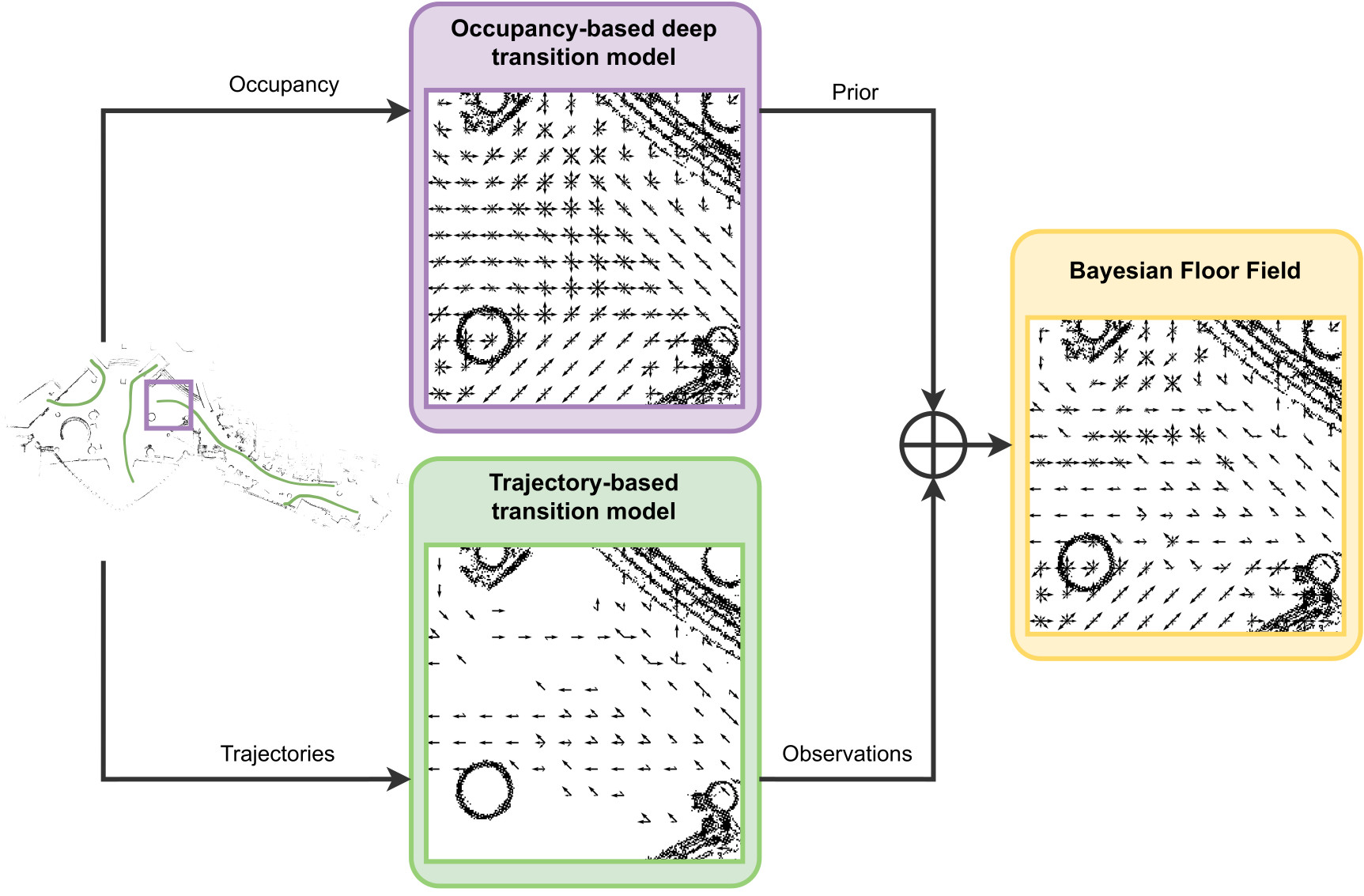 Bayesian Floor Field: Transferring people flow predictions across environmentsFrancesco Verdoja, Tomasz Piotr Kucner, and Ville KyrkiIn 2024 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2024
Bayesian Floor Field: Transferring people flow predictions across environmentsFrancesco Verdoja, Tomasz Piotr Kucner, and Ville KyrkiIn 2024 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2024Mapping people dynamics is a crucial skill for robots, because it enables them to coexist in human-inhabited environments. However, learning a model of people dynamics is a time consuming process which requires observation of large amount of people moving in an environment. Moreover, approaches for mapping dynamics are unable to transfer the learned models across environments: each model is only able to describe the dynamics of the environment it has been built in. However, the impact of architectural geometry on people’s movement can be used to anticipate their patterns of dynamics, and recent work has looked into learning maps of dynamics from occupancy. So far however, approaches based on trajectories and those based on geometry have not been combined. In this work we propose a novel Bayesian approach to learn people dynamics able to combine knowledge about the environment geometry with observations from human trajectories. An occupancy-based deep prior is used to build an initial transition model without requiring any observations of pedestrian; the model is then updated when observations become available using Bayesian inference. We demonstrate the ability of our model to increase data efficiency and to generalize across real large-scale environments, which is unprecedented for maps of dynamics.
@inproceedings{202410_verdoja_bayesian, address = {Abu Dhabi, UAE}, title = {Bayesian Floor Field: Transferring people flow predictions across environments}, doi = {10.1109/IROS58592.2024.10802300}, booktitle = {2024 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Verdoja, Francesco and Kucner, Tomasz Piotr and Kyrki, Ville}, month = oct, year = {2024}, pages = {12801--12807}, } - MFI
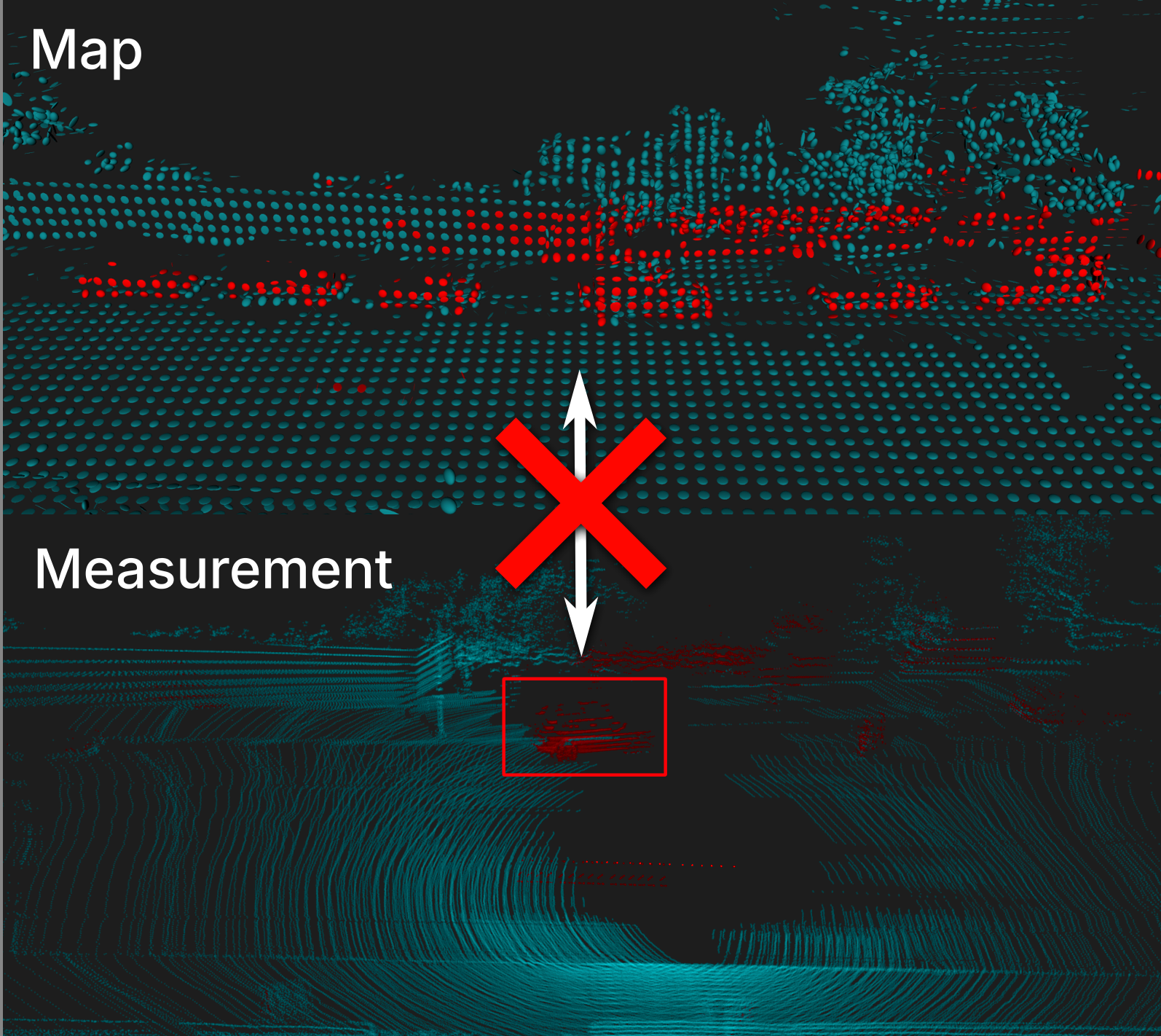 Localization Under Consistent Assumptions Over DynamicsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiIn 2024 IEEE Int. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), Sep 2024
Localization Under Consistent Assumptions Over DynamicsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiIn 2024 IEEE Int. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), Sep 2024Accurate maps are a prerequisite for virtually all mobile robot tasks. Most state-of-the-art maps assume a static world; therefore, dynamic objects are filtered out of the measurements. However, this division ignores movable but non- moving—i.e., semi-static—objects, which are usually recorded in the map and treated as static objects, violating the static world assumption and causing errors in the localization. This paper presents a method for consistently modeling moving and movable objects to match the map and measurements. This reduces the error resulting from inconsistent categorization and treatment of non-static measurements. A semantic segmentation network is used to categorize the measurements into static and semi-static classes, and a background subtraction filter is used to remove dynamic measurements. Finally, we show that consis- tent assumptions over dynamics improve localization accuracy when compared against a state-of-the-art baseline solution using real-world data from the Oxford Radar RobotCar data set.
@inproceedings{202409_pekkanen_localization, address = {Pilsen, Czechia}, title = {Localization {Under} {Consistent} {Assumptions} {Over} {Dynamics}}, doi = {10.1109/MFI62651.2024.10705760}, booktitle = {2024 {IEEE} {Int.} {Conf.} on {Multisensor} {Fusion} and {Integration} for {Intelligent} {Systems} ({MFI})}, publisher = {IEEE}, author = {Pekkanen, Matti and Verdoja, Francesco and Kyrki, Ville}, month = sep, year = {2024}, } - MFI
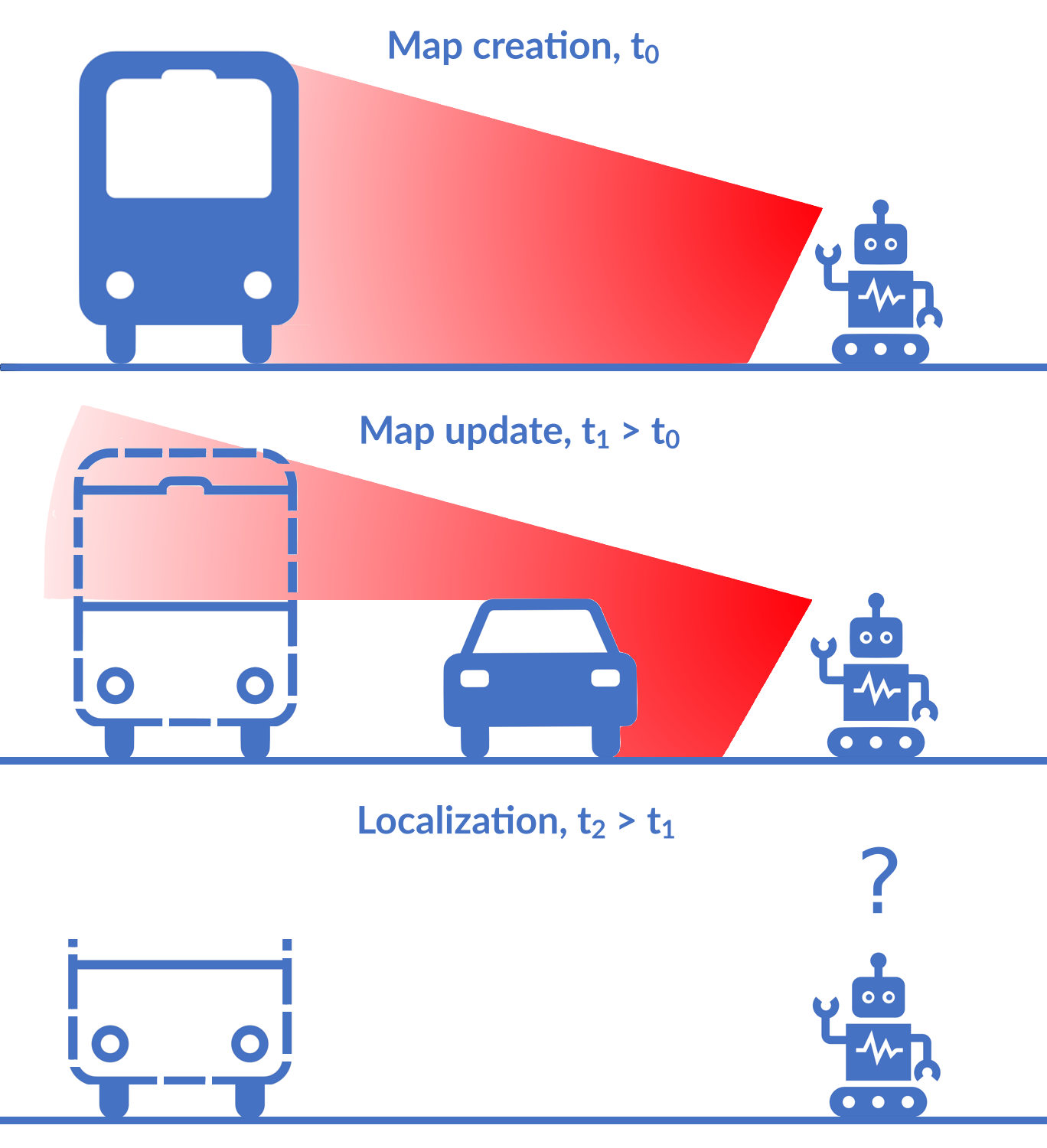 Object-Oriented Grid Mapping in Dynamic EnvironmentsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiIn 2024 IEEE Int. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), Sep 2024
Object-Oriented Grid Mapping in Dynamic EnvironmentsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiIn 2024 IEEE Int. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), Sep 2024Grid maps, especially occupancy grid maps, are ubiquitous in many mobile robot applications. To simplify the process of learning the map, grid maps subdivide the world into a grid of cells whose occupancies are independently estimated using measurements in the perceptual field of the particular cell. However, the world consists of objects that span multiple cells, which means that measurements falling onto a cell provide evidence of the occupancy of other cells belonging to the same object. Current models do not capture this correlation and, therefore, do not use object-level information for estimating the state of the environment. In this work, we present a way to generalize the update of grid maps, relaxing the assumption of independence. We propose modeling the relationship between the measurements and the occupancy of each cell as a set of latent variables and jointly estimate those variables and the posterior of the map. We propose a method to estimate the latent variables by clustering based on semantic labels and an extension to the Normal Distributions Transform Occupancy Map (NDT-OM) to facilitate the proposed map update method. We perform comprehensive map creation and localization ex- periments with real-world data sets and show that the proposed method creates better maps in highly dynamic environments compared to state-of-the-art methods. Finally, we demonstrate the ability of the proposed method to remove occluded objects from the map in a lifelong map update scenario.
@inproceedings{202409_pekkanen_object, address = {Pilsen, Czechia}, title = {Object-{Oriented} {Grid} {Mapping} in {Dynamic} {Environments}}, doi = {10.1109/MFI62651.2024.10705762}, booktitle = {2024 {IEEE} {Int.} {Conf.} on {Multisensor} {Fusion} and {Integration} for {Intelligent} {Systems} ({MFI})}, publisher = {IEEE}, author = {Pekkanen, Matti and Verdoja, Francesco and Kyrki, Ville}, month = sep, year = {2024}, }
workshop articles
- ICRA
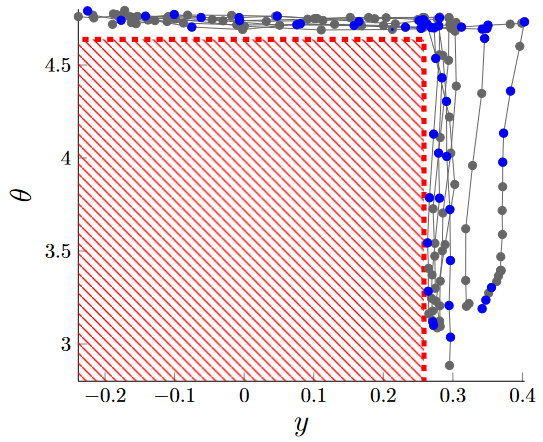 Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory GenerationShivam Chaubey, Francesco Verdoja, and Ville KyrkiMay 2024Presented at the “Towards Collaborative Partners: Design, Shared Control, and Robot Learning for Physical Human-Robot Interaction (pHRI)” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)
Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory GenerationShivam Chaubey, Francesco Verdoja, and Ville KyrkiMay 2024Presented at the “Towards Collaborative Partners: Design, Shared Control, and Robot Learning for Physical Human-Robot Interaction (pHRI)” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)Learning from Demonstration (LfD) allows robots to mimic human actions. However, these methods do not model constraints crucial to ensure safety of the learned skill. Moreover, even when explicitly modelling constraints, they rely on the assumption of a known cost function, which limits their practical usability for task with unknown cost. In this work we propose a two-step optimization process that allow to estimate cost and constraints by decoupling the learning of cost functions from the identification of unknown constraints within the demonstrated trajectories. Initially, we identify the cost function by isolating the effect of constraints on parts of the demonstrations. Subsequently, a constraint leaning method is used to identify the unknown constraints. Our approach is validated both on simulated trajectories and a real robotic manipulation task. Our experiments show the impact that incorrect cost estimation has on the learned constraints and illustrate how the proposed method is able to infer unknown constraints, such as obstacles, from demonstrated trajectories without any initial knowledge of the cost.
@online{202405_chaubey_jointly, title = {Jointly Learning Cost and Constraints from Demonstrations for Safe Trajectory Generation}, url = {https://sites.google.com/view/icra24-physical-hri}, author = {Chaubey, Shivam and Verdoja, Francesco and Kyrki, Ville}, month = may, year = {2024}, note = {Presented at the ``Towards Collaborative Partners: Design, Shared Control, and Robot Learning for Physical Human-Robot Interaction (pHRI)'' workshop at the IEEE Int.\ Conf.\ on Robotics and Automation (ICRA)}, } - ICRA
 Evaluating the quality of robotic visual-language mapsMatti Pekkanen, Tsvetomila Mihaylova, Francesco Verdoja, and Ville KyrkiMay 2024Presented at the “Vision-Language Models for Navigation and Manipulation (VLMNM)” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)
Evaluating the quality of robotic visual-language mapsMatti Pekkanen, Tsvetomila Mihaylova, Francesco Verdoja, and Ville KyrkiMay 2024Presented at the “Vision-Language Models for Navigation and Manipulation (VLMNM)” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)Visual-language models (VLMs) have recently been introduced in robotic mapping by using the latent representations, i.e., embeddings, of the VLMs to represent the natural language semantics in the map. The main benefit is moving beyond a small set of human-created labels toward open-vocabulary scene understanding. While there is anecdotal evidence that maps built this way support downstream tasks, such as navigation, rigorous analysis of the quality of the maps using these embeddings is lacking. In this paper, we propose a way to analyze the quality of maps created using VLMs by evaluating two critical properties: queryability and consistency. We demonstrate the proposed method by evaluating the maps created by two state-of-the-art methods, VLMaps and OpenScene, using two encoders, LSeg and OpenSeg, using real-world data from the Matterport3D data set. We find that OpenScene outperforms VLMaps with both encoders, and LSeg outperforms OpenSeg with both methods.
@online{202405_pekkanen_evaluating, title = {Evaluating the quality of robotic visual-language maps}, url = {https://vlmnm-workshop.github.io}, author = {Pekkanen, Matti and Mihaylova, Tsvetomila and Verdoja, Francesco and Kyrki, Ville}, month = may, year = {2024}, note = {Presented at the ``Vision-Language Models for Navigation and Manipulation (VLMNM)'' workshop at the IEEE Int.\ Conf.\ on Robotics and Automation (ICRA)}, } - ICRA
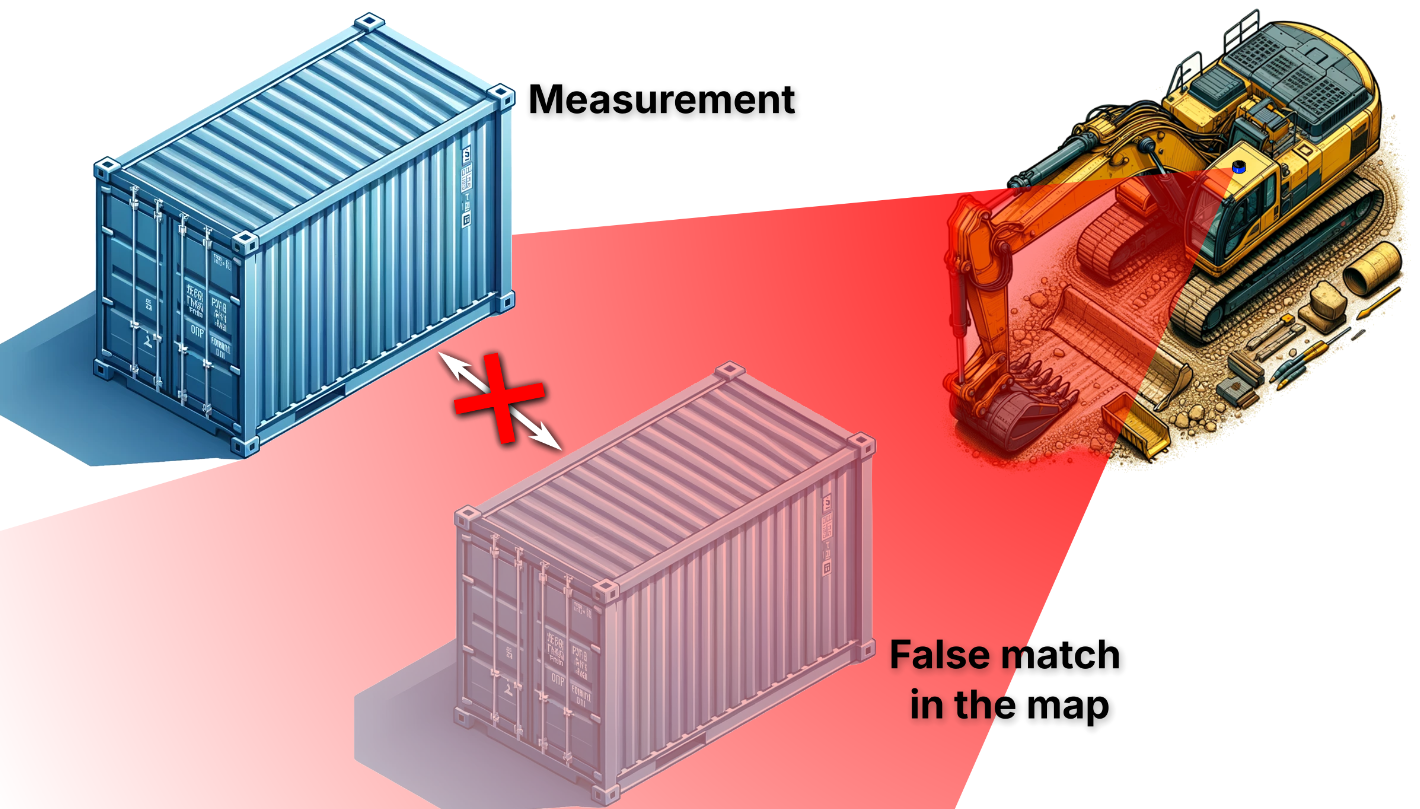 Modeling movable objects improves localization in dynamic environmentsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiMay 2024Presented at the “Future of Construction: Lifelong Learning Robots in Changing Construction Sites” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)
Modeling movable objects improves localization in dynamic environmentsMatti Pekkanen, Francesco Verdoja, and Ville KyrkiMay 2024Presented at the “Future of Construction: Lifelong Learning Robots in Changing Construction Sites” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)Most state-of-the-art robotic maps assume a static world; therefore, dynamic objects are filtered out of the measurements. However, this division ignores movable but non- moving, i.e., semi-static objects, which are usually recorded in the map and treated as static objects, violating the static world assumption and causing errors in the localization. This paper presents a method for modeling moving and movable objects to match the map and measurements consistently. This reduces the error resulting from inconsistent categorization and treatment of non-static measurements. A semantic segmentation network is used to categorize the measurements into static and semi- static classes, and a background subtraction-based filtering method is used to remove dynamic measurements. Experimental comparison against a state-of-the-art baseline solution using real-world data from the Oxford Radar RobotCar data set shows that consistent assumptions over dynamics increase localization accuracy.
@online{202405_pekkanen_modeling, title = {Modeling movable objects improves localization in dynamic environments}, url = {https://construction-robots.github.io}, author = {Pekkanen, Matti and Verdoja, Francesco and Kyrki, Ville}, month = may, year = {2024}, note = {Presented at the ``Future of Construction: Lifelong Learning Robots in Changing Construction Sites'' workshop at the IEEE Int.\ Conf.\ on Robotics and Automation (ICRA)}, } - ICRA
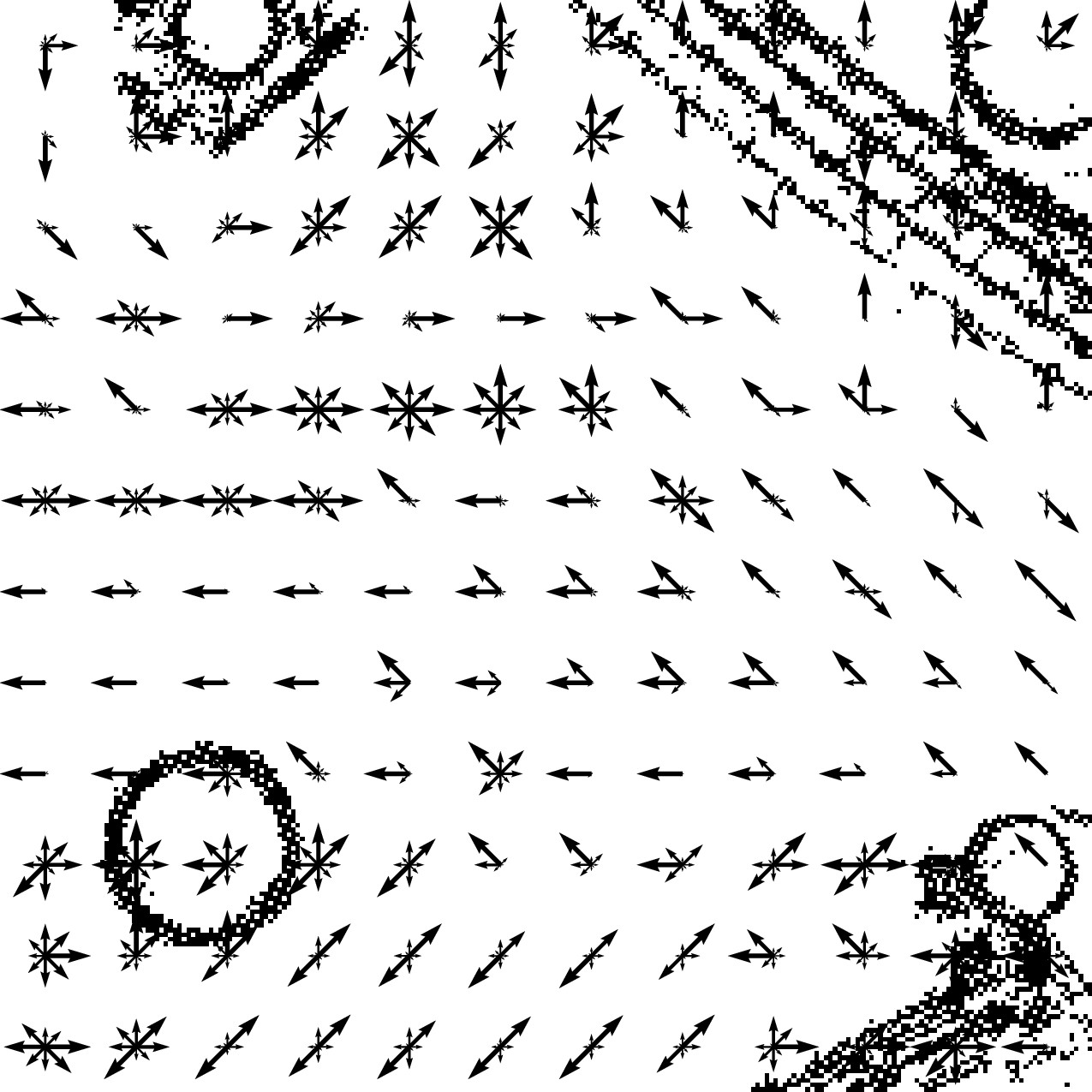 Using occupancy priors to generalize people flow predictionsFrancesco Verdoja, Tomasz Piotr Kucner, and Ville KyrkiMay 2024Presented at the “Long-term Human Motion Prediction” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)
Using occupancy priors to generalize people flow predictionsFrancesco Verdoja, Tomasz Piotr Kucner, and Ville KyrkiMay 2024Presented at the “Long-term Human Motion Prediction” workshop at the IEEE Int. Conf. on Robotics and Automation (ICRA)Mapping people dynamics is a crucial skill for robots, because it enables them to coexist in human-inhabited environments. However, learning a model of people dynamics is a time consuming process which requires observation of large amount of people moving in an environment. Moreover, approaches for mapping dynamics are unable to transfer the learned models across environments: each model is only able to describe the dynamics of the environment it has been built in. However, the impact of architectural geometry on people’s movement can be used to anticipate their patterns of dynamics, and recent work has looked into learning maps of dynamics from occupancy. So far however, approaches based on trajectories and those based on geometry have not been combined. In this work we propose a novel Bayesian approach to learn people dynamics able to combine knowledge about the environment geometry with observations from human trajectories. An occupancy-based deep prior is used to build an initial transition model without requiring any observations of pedestrian; the model is then updated when observations become available using Bayesian inference. We demonstrate the ability of our model to increase data efficiency and to generalize across real large-scale environments, which is unprecedented for maps of dynamics.
@online{202405_verdoja_using, title = {Using occupancy priors to generalize people flow predictions}, url = {https://motionpredictionicra2024.github.io}, author = {Verdoja, Francesco and Kucner, Tomasz Piotr and Kyrki, Ville}, month = may, year = {2024}, note = {Presented at the ``Long-term Human Motion Prediction'' workshop at the IEEE Int.\ Conf.\ on Robotics and Automation (ICRA)}, }
2023
journal articles
- RAS
 LSVL: Large-scale season-invariant visual localization for UAVsJouko Kinnari, Riccardo Renzulli, Francesco Verdoja, and Ville KyrkiRobotics and Autonomous Systems, Oct 2023
LSVL: Large-scale season-invariant visual localization for UAVsJouko Kinnari, Riccardo Renzulli, Francesco Verdoja, and Ville KyrkiRobotics and Autonomous Systems, Oct 2023Localization of autonomous unmanned aerial vehicles (UAVs) relies heavily on Global Navigation Satellite Systems (GNSS), which are susceptible to interference. Especially in security applications, robust localization algorithms independent of GNSS are needed to provide dependable operations of autonomous UAVs also in interfered conditions. Typical non-GNSS visual localization approaches rely on known starting pose, work only on a small-sized map, or require known flight paths before a mission starts. We consider the problem of localization with no information on initial pose or planned flight path. We propose a solution for global visual localization on a map at scale up to 100 km2, based on matching orthoprojected UAV images to satellite imagery using learned season-invariant descriptors. We show that the method is able to determine heading, latitude and longitude of the UAV at 12.6-18.7 m lateral translation error in as few as 23.2-44.4 updates from an uninformed initialization, also in situations of significant seasonal appearance difference (winter-summer) between the UAV image and the map. We evaluate the characteristics of multiple neural network architectures for generating the descriptors, and likelihood estimation methods that are able to provide fast convergence and low localization error. We also evaluate the operation of the algorithm using real UAV data and evaluate running time on a real-time embedded platform. We believe this is the first work that is able to recover the pose of an UAV at this scale and rate of convergence, while allowing significant seasonal difference between camera observations and map.
@article{202310_kinnari_lsvl, title = {{LSVL}: {Large}-scale season-invariant visual localization for {UAVs}}, volume = {168}, doi = {10.1016/j.robot.2023.104497}, journal = {Robotics and Autonomous Systems}, author = {Kinnari, Jouko and Renzulli, Riccardo and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2023}, } - IJRR
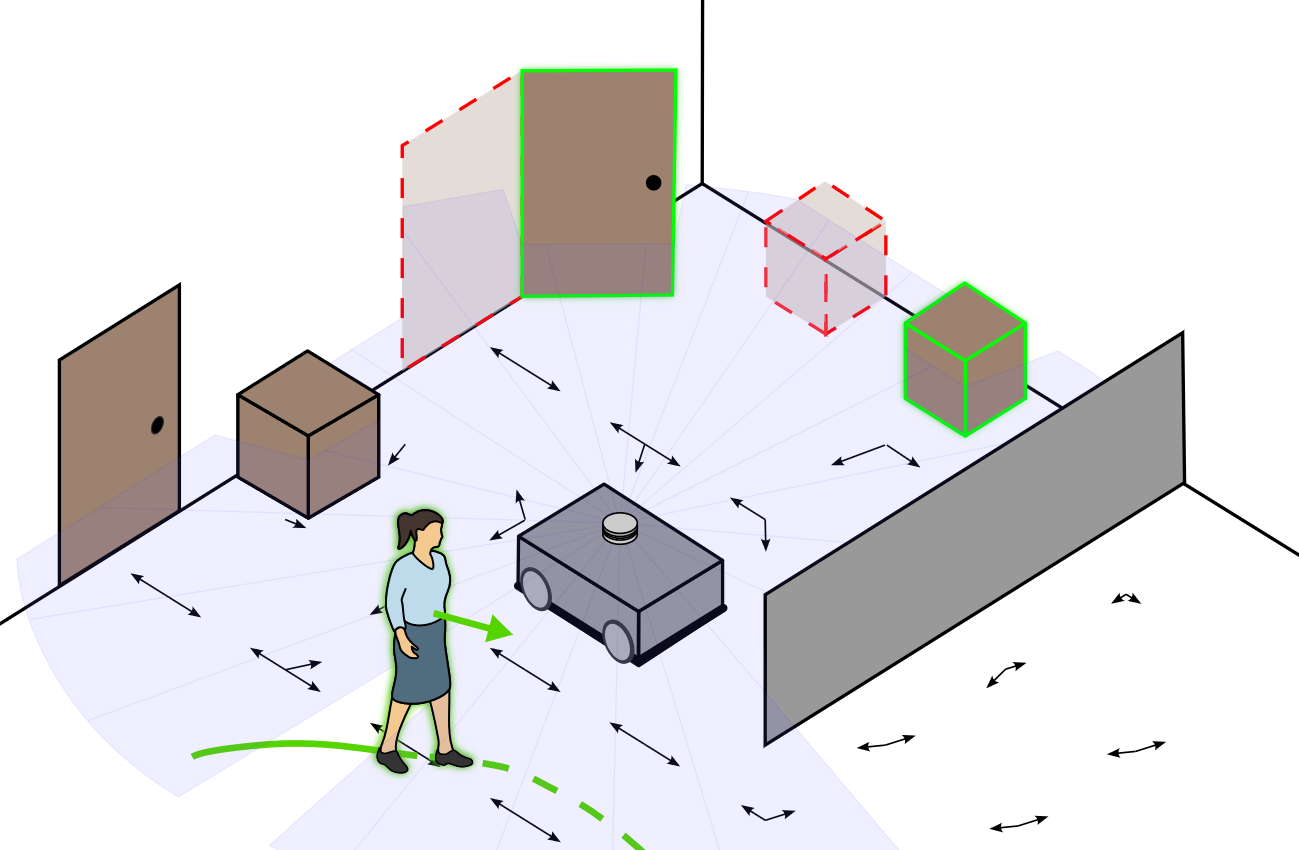 Survey of maps of dynamics for mobile robotsTomasz Piotr Kucner, Martin Magnusson, Sariah Mghames, Luigi Palmieri, Francesco Verdoja, and 6 more authorsThe Int. Journal of Robotics Research, Sep 2023
Survey of maps of dynamics for mobile robotsTomasz Piotr Kucner, Martin Magnusson, Sariah Mghames, Luigi Palmieri, Francesco Verdoja, and 6 more authorsThe Int. Journal of Robotics Research, Sep 2023Robotic mapping provides spatial information for autonomous agents. Depending on the tasks they seek to enable, the maps created range from simple 2D representations of the environment geometry to complex, multilayered semantic maps. This survey article is about maps of dynamics (MoDs), which store semantic information about typical motion patterns in a given environment. Some MoDs use trajectories as input, and some can be built from short, disconnected observations of motion. Robots can use MoDs, for example, for global motion planning, improved localization, or human motion prediction. Accounting for the increasing importance of maps of dynamics, we present a comprehensive survey that organizes the knowledge accumulated in the field and identifies promising directions for future work. Specifically, we introduce field-specific vocabulary, summarize existing work according to a novel taxonomy, and describe possible applications and open research problems. We conclude that the field is mature enough, and we expect that maps of dynamics will be increasingly used to improve robot performance in real-world use cases. At the same time, the field is still in a phase of rapid development where novel contributions could significantly impact this research area.
@article{202309_kucner_survey, title = {Survey of maps of dynamics for mobile robots}, volume = {42}, doi = {10.1177/02783649231190428}, number = {11}, journal = {The Int.\ Journal of Robotics Research}, author = {Kucner, Tomasz Piotr and Magnusson, Martin and Mghames, Sariah and Palmieri, Luigi and Verdoja, Francesco and Swaminathan, Chittaranjan Srinivas and Krajník, Tomáš and Schaffernicht, Erik and Bellotto, Nicola and Hanheide, Marc and Lilienthal, Achim J}, month = sep, year = {2023}, pages = {977--1006}, }
conference articles
- IROS
 Constrained Generative Sampling of 6-DoF GraspsJens Lundell, Francesco Verdoja, Tran Nguyen Le, Arsalan Mousavian, Dieter Fox, and 1 more authorIn 2023 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2023
Constrained Generative Sampling of 6-DoF GraspsJens Lundell, Francesco Verdoja, Tran Nguyen Le, Arsalan Mousavian, Dieter Fox, and 1 more authorIn 2023 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2023Most state-of-the-art data-driven grasp sampling methods propose stable and collision-free grasps uniformly on the target object. For bin-picking, executing any of those reachable grasps is sufficient. However, for completing specific tasks, such as squeezing out liquid from a bottle, we want the grasp to be on a specific part of the object’s body while avoiding other locations, such as the cap. This work presents a generative grasp sampling network, VCGS, capable of constrained 6 Degrees of Freedom (DoF) grasp sampling. In addition, we also curate a new dataset designed to train and evaluate methods for constrained grasping. The new dataset, called CONG, consists of over 14 million training samples of synthetically rendered point clouds and grasps at random target areas on 2889 objects. VCGS is benchmarked against GraspNet, a state-of-the-art unconstrained grasp sampler, in simulation and on a real robot. The results demonstrate that VCGS achieves a 10-15% higher grasp success rate than the baseline while being 2-3 times as sample efficient. Supplementary material is available on our project website.
@inproceedings{202310_lundell_constrained, address = {Detroit, USA}, title = {Constrained {Generative} {Sampling} of 6-{DoF} {Grasps}}, doi = {10.1109/IROS55552.2023.10341344}, booktitle = {2023 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Lundell, Jens and Verdoja, Francesco and Nguyen Le, Tran and Mousavian, Arsalan and Fox, Dieter and Kyrki, Ville}, month = oct, year = {2023}, pages = {2940--2946}, }
2022
journal articles
- RA-L
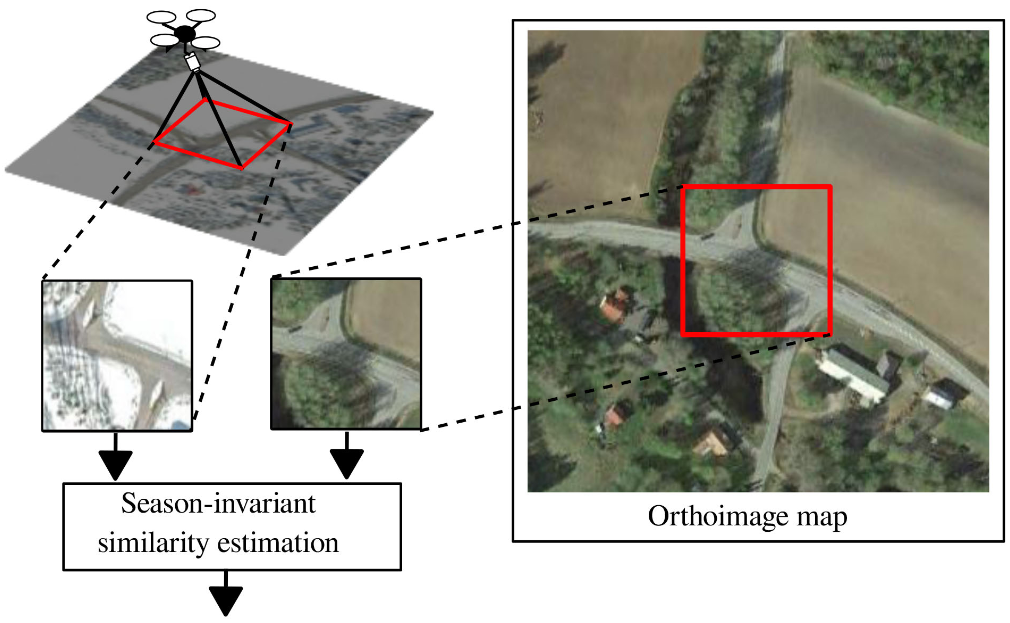 Season-Invariant GNSS-Denied Visual Localization for UAVsJouko Kinnari, Francesco Verdoja, and Ville KyrkiIEEE Robotics and Automation Letters, Oct 2022
Season-Invariant GNSS-Denied Visual Localization for UAVsJouko Kinnari, Francesco Verdoja, and Ville KyrkiIEEE Robotics and Automation Letters, Oct 2022Awarded by the IEEE Finland CSS/RAS/SMCS Joint Chapter
Localization without Global Navigation Satellite Systems (GNSS) is a critical functionality in autonomous operations of unmanned aerial vehicles (UAVs). Vision-based localization on a known map can be an effective solution, but it is burdened by two main problems: places have different appearance depending on weather and season, and the perspective discrepancy between the UAV camera image and the map make matching hard. In this work, we propose a localization solution relying on matching of UAV camera images to georeferenced orthophotos with a trained convolutional neural network model that is invariant to significant seasonal appearance difference (winter-summer) between the camera image and map. We compare the convergence speed and localization accuracy of our solution to six reference methods. The results show major improvements with respect to reference methods, especially under high seasonal variation. We finally demonstrate the ability of the method to successfully localize a real UAV, showing that the proposed method is robust to perspective changes.
@article{202210_kinnari_season-invariant, title = {Season-{Invariant} {GNSS}-{Denied} {Visual} {Localization} for {UAVs}}, volume = {7}, doi = {10.1109/LRA.2022.3191038}, number = {4}, journal = {IEEE Robotics and Automation Letters}, publisher = {IEEE}, author = {Kinnari, Jouko and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2022}, pages = {10232--10239}, }
conference articles
- RO-MAN
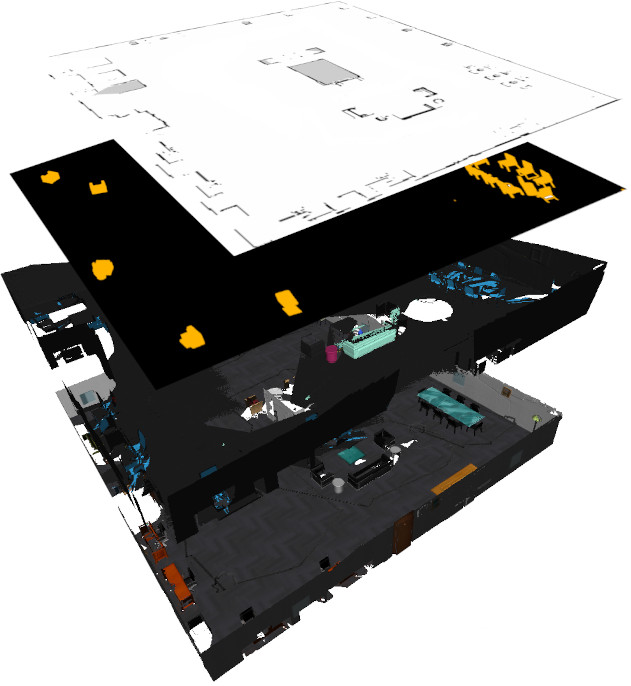 Augmented Environment Representations with Complete Object ModelsKrishnananda Prabhu Sivananda, Francesco Verdoja, and Ville KyrkiIn 2022 IEEE Int. Conf. on Robot and Human Interactive Communication (RO-MAN), Aug 2022
Augmented Environment Representations with Complete Object ModelsKrishnananda Prabhu Sivananda, Francesco Verdoja, and Ville KyrkiIn 2022 IEEE Int. Conf. on Robot and Human Interactive Communication (RO-MAN), Aug 2022While 2D occupancy maps commonly used in mobile robotics enable safe navigation in indoor environments, in order for robots to understand and interact with their environment and its inhabitants representing 3D geometry and semantic environment information is required. Semantic information is crucial in effective interpretation of the meanings humans attribute to different parts of a space, while 3D geometry is important for safety and high-level understanding. We propose a pipeline that can generate a multi-layer representation of indoor environments for robotic applications. The proposed representation includes 3D metric-semantic layers, a 2D occupancy layer, and an object instance layer where known objects are replaced with an approximate model obtained through a novel model-matching approach. The metric-semantic layer and the object instance layer are combined to form an augmented representation of the environment. Experiments show that the proposed shape matching method outperforms a state-of-the-art deep learning method when tasked to complete unseen parts of objects in the scene. The pipeline performance translates well from simulation to real world as shown by F1-score analysis, with semantic segmentation accuracy using Mask R-CNN acting as the major bottleneck. Finally, we also demonstrate on a real robotic platform how the multi-layer map can be used to improve navigation safety.
@inproceedings{202208_sivananda_augmented, address = {Naples, Italy}, title = {Augmented {Environment} {Representations} with {Complete} {Object} {Models}}, doi = {10.1109/RO-MAN53752.2022.9900516}, booktitle = {2022 {IEEE} {Int.}\ {Conf.}\ on {Robot} and {Human} {Interactive} {Communication} ({RO}-{MAN})}, publisher = {IEEE}, author = {Sivananda, Krishnananda Prabhu and Verdoja, Francesco and Kyrki, Ville}, month = aug, year = {2022}, pages = {1123--1130}, }
workshop articles
- IROS
 Generating people flow from architecture of real unseen environmentsFrancesco Verdoja, Tomasz Piotr Kucner, and Ville KyrkiOct 2022Presented at the “Perception and Navigation for Autonomous Robotics in Unstructured and Dynamic Environments (PNARUDE)” workshop at the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)
Generating people flow from architecture of real unseen environmentsFrancesco Verdoja, Tomasz Piotr Kucner, and Ville KyrkiOct 2022Presented at the “Perception and Navigation for Autonomous Robotics in Unstructured and Dynamic Environments (PNARUDE)” workshop at the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS)Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
@online{202210_verdoja_generating, title = {Generating people flow from architecture of real unseen environments}, url = {https://iros2022-pnarude.github.io}, author = {Verdoja, Francesco and Kucner, Tomasz Piotr and Kyrki, Ville}, month = oct, year = {2022}, note = {Presented at the ``Perception and Navigation for Autonomous Robotics in Unstructured and Dynamic Environments (PNARUDE)'' workshop at the IEEE/RSJ Int.\ Conf.\ on Intelligent Robots and Systems (IROS)}, }
2021
journal articles
- RA-L
 DDGC: Generative Deep Dexterous Grasping in ClutterJens Lundell, Francesco Verdoja, and Ville KyrkiIEEE Robotics and Automation Letters, Oct 2021
DDGC: Generative Deep Dexterous Grasping in ClutterJens Lundell, Francesco Verdoja, and Ville KyrkiIEEE Robotics and Automation Letters, Oct 2021Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
@article{202110_lundell_ddgc, title = {{DDGC}: {Generative} {Deep} {Dexterous} {Grasping} in {Clutter}}, volume = {6}, shorttitle = {{DDGC}}, doi = {10.1109/LRA.2021.3096239}, number = {4}, journal = {IEEE Robotics and Automation Letters}, publisher = {IEEE}, author = {Lundell, Jens and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2021}, pages = {6899--6906}, } - RA-L
 Probabilistic Surface Friction Estimation Based on Visual and Haptic MeasurementsTran Nguyen Le, Francesco Verdoja, Fares J. Abu-Dakka, and Ville KyrkiIEEE Robotics and Automation Letters, Apr 2021
Probabilistic Surface Friction Estimation Based on Visual and Haptic MeasurementsTran Nguyen Le, Francesco Verdoja, Fares J. Abu-Dakka, and Ville KyrkiIEEE Robotics and Automation Letters, Apr 2021Accurately modeling local surface properties of objects is crucial to many robotic applications, from grasping to material recognition. Surface properties like friction are however difficult to estimate, as visual observation of the object does not convey enough information over these properties. In contrast, haptic exploration is time consuming as it only provides information relevant to the explored parts of the object. In this work, we propose a joint visuo-haptic object model that enables the estimation of surface friction coefficient over an entire object by exploiting the correlation of visual and haptic information, together with a limited haptic exploration by a robotic arm. We demonstrate the validity of the proposed method by showing its ability to estimate varying friction coefficients on a range of real multi-material objects. Furthermore, we illustrate how the estimated friction coefficients can improve grasping success rate by guiding a grasp planner toward high friction areas.
@article{202104_nguyen_le_probabilistic, title = {Probabilistic {Surface} {Friction} {Estimation} {Based} on {Visual} and {Haptic} {Measurements}}, volume = {6}, doi = {10.1109/LRA.2021.3062585}, number = {2}, journal = {IEEE Robotics and Automation Letters}, publisher = {IEEE}, author = {Nguyen Le, Tran and Verdoja, Francesco and Abu-Dakka, Fares J. and Kyrki, Ville}, month = apr, year = {2021}, pages = {2838--2845}, }
conference articles
- ICAR
 GNSS-denied geolocalization of UAVs by visual matching of onboard camera images with orthophotosJouko Kinnari, Francesco Verdoja, and Ville KyrkiIn 2021 IEEE Int. Conf. on Advanced Robotics (ICAR), Dec 2021
GNSS-denied geolocalization of UAVs by visual matching of onboard camera images with orthophotosJouko Kinnari, Francesco Verdoja, and Ville KyrkiIn 2021 IEEE Int. Conf. on Advanced Robotics (ICAR), Dec 2021Localization of low-cost Unmanned Aerial Vehicles (UAVs) often relies on Global Navigation Satellite Systems (GNSS). GNSS are susceptible to both natural disruptions to radio signal and intentional jamming and spoofing by an adversary. A typical way to provide georeferenced localization without GNSS for small UAVs is to have a downward-facing camera and match camera images to a map. The downward-facing camera adds cost, size, and weight to the UAV platform and the orientation limits its usability for other purposes. In this work, we propose a Monte-Carlo localization method for georeferenced localization of an UAV requiring no infrastructure using only inertial measurements, a camera facing an arbitrary direction, and an orthoimage map. We perform orthorectification of the UAV image, relying on a local planarity assumption of the environment, relaxing the requirement of downward-pointing camera. We propose a measure of goodness for the matching score of an orthorectified UAV image and a map. We demonstrate that the system is able to localize globally an UAV with modest requirements for initialization and map resolution.
@inproceedings{202112_kinnari_gnss-denied, title = {{GNSS}-denied geolocalization of {UAVs} by visual matching of onboard camera images with orthophotos}, doi = {10.1109/ICAR53236.2021.9659333}, booktitle = {2021 {IEEE} {Int.} {Conf.} on {Advanced} {Robotics} ({ICAR})}, publisher = {IEEE}, author = {Kinnari, Jouko and Verdoja, Francesco and Kyrki, Ville}, month = dec, year = {2021}, pages = {555--562}, } - ECMR
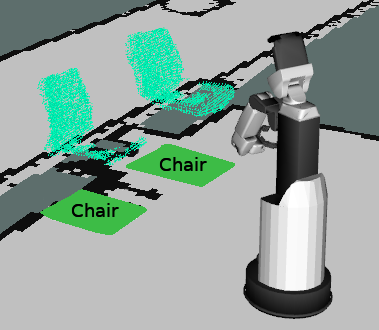 Online Object-Oriented Semantic Mapping and Map UpdatingNils Dengler, Tobias Zaenker, Francesco Verdoja, and Maren BennewitzIn 2021 Eur. Conf. on Mobile Robots (ECMR), Aug 2021
Online Object-Oriented Semantic Mapping and Map UpdatingNils Dengler, Tobias Zaenker, Francesco Verdoja, and Maren BennewitzIn 2021 Eur. Conf. on Mobile Robots (ECMR), Aug 2021Creating and maintaining an accurate representation of the environment is an essential capability for every service robot. Especially for household robots acting in indoor environments, semantic information is important. In this paper, we present a semantic mapping framework with modular map representations. Our system is capable of online mapping and object updating given object detections from RGB-D data and provides various 2D and 3D representations of the mapped objects. To undo wrong data associations, we perform a refinement step when updating object shapes. Furthermore, we maintain an existence likelihood for each object to deal with false positive and false negative detections and keep the map updated. Our mapping system is highly efficient and achieves a run time of more than 10 Hz. We evaluated our approach in various environments using two different robots, i.e., a Toyota HSR and a Fraunhofer Care-O-Bot-4. As the experimental results demonstrate, our system is able to generate maps that are close to the ground truth and outperforms an existing approach in terms of intersection over union, different distance metrics, and the number of correct object mappings.
@inproceedings{202108_dengler_online, title = {Online {Object}-{Oriented} {Semantic} {Mapping} and {Map} {Updating}}, doi = {10.1109/ECMR50962.2021.9568817}, booktitle = {2021 {Eur.} {Conf.} on {Mobile} {Robots} ({ECMR})}, author = {Dengler, Nils and Zaenker, Tobias and Verdoja, Francesco and Bennewitz, Maren}, month = aug, year = {2021}, } - ICRA
 Multi-FinGAN: Generative Coarse-To-Fine Sampling of Multi-Finger GraspsJens Lundell, Enric Corona, Tran Nguyen Le, Francesco Verdoja, Philippe Weinzaepfel, and 3 more authorsIn 2021 IEEE Int. Conf. on Robotics and Automation (ICRA), May 2021
Multi-FinGAN: Generative Coarse-To-Fine Sampling of Multi-Finger GraspsJens Lundell, Enric Corona, Tran Nguyen Le, Francesco Verdoja, Philippe Weinzaepfel, and 3 more authorsIn 2021 IEEE Int. Conf. on Robotics and Automation (ICRA), May 2021While there exists many methods for manipulating rigid objects with parallel-jaw grippers, grasping with multi-finger robotic hands remains a quite unexplored research topic. Reasoning and planning collision-free trajectories on the additional degrees of freedom of several fingers represents an important challenge that, so far, involves computationally costly and slow processes. In this work, we present Multi-FinGAN, a fast generative multi-finger grasp sampling method that synthesizes high quality grasps directly from RGB-D images in about a second. We achieve this by training in an end-to-end fashion a coarse-to-fine model composed of a classification network that distinguishes grasp types according to a specific taxonomy and a refinement network that produces refined grasp poses and joint angles. We experimentally validate and benchmark our method against a standard grasp-sampling method on 790 grasps in simulation and 20 grasps on a real Franka Emika Panda. All experimental results using our method show consistent improvements both in terms of grasp quality metrics and grasp success rate. Remarkably, our approach is up to 20-30 times faster than the baseline, a significant improvement that opens the door to feedback-based grasp re-planning and task informative grasping. Code is available at this https URL.
@inproceedings{202105_lundell_multi-fingan, title = {Multi-{FinGAN}: {Generative} {Coarse}-{To}-{Fine} {Sampling} of {Multi}-{Finger} {Grasps}}, shorttitle = {Multi-{FinGAN}}, doi = {10.1109/ICRA48506.2021.9561228}, booktitle = {2021 {IEEE} {Int.} {Conf.} on {Robotics} and {Automation} ({ICRA})}, publisher = {IEEE}, author = {Lundell, Jens and Corona, Enric and Nguyen Le, Tran and Verdoja, Francesco and Weinzaepfel, Philippe and Rogez, Grégory and Moreno-Noguer, Francesc and Kyrki, Ville}, month = may, year = {2021}, pages = {4495--4501}, }
workshop articles
- ICML
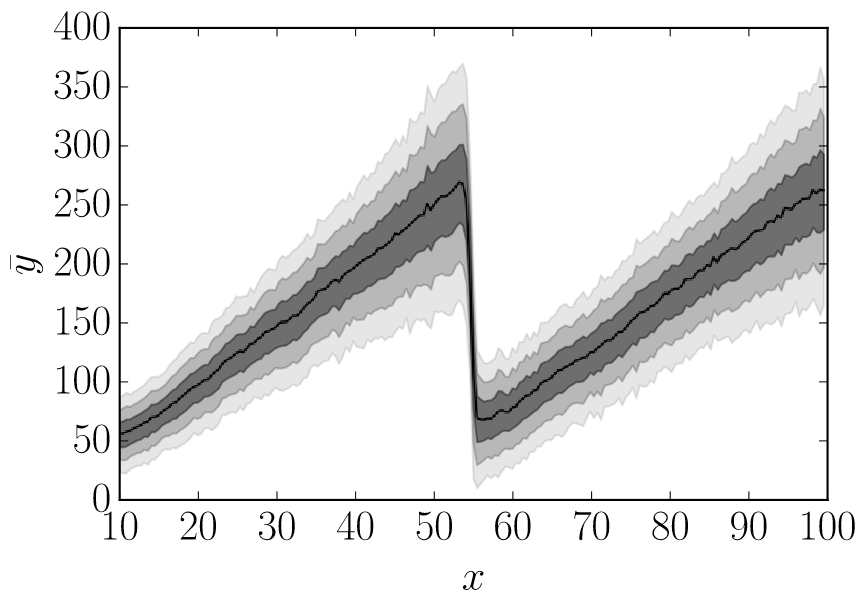 Notes on the Behavior of MC DropoutFrancesco Verdoja and Ville KyrkiJul 2021Presented at the “Uncertainty and Robustness in Deep Learning (UDL)” workshop at the 2021 Int. Conf. on Machine Learning (ICML)
Notes on the Behavior of MC DropoutFrancesco Verdoja and Ville KyrkiJul 2021Presented at the “Uncertainty and Robustness in Deep Learning (UDL)” workshop at the 2021 Int. Conf. on Machine Learning (ICML)Among the various options to estimate uncertainty in deep neural networks, Monte-Carlo dropout is widely popular for its simplicity and effectiveness. However the quality of the uncertainty estimated through this method varies and choices in architecture design and in training procedures have to be carefully considered and tested to obtain satisfactory results. In this paper we present a study offering a different point of view on the behavior of Monte-Carlo dropout, which enables us to observe a few interesting properties of the technique to keep in mind when considering its use for uncertainty estimation.
@online{202107_verdoja_notes, title = {Notes on the {Behavior} of {MC} {Dropout}}, url = {https://sites.google.com/view/udlworkshop2021}, author = {Verdoja, Francesco and Kyrki, Ville}, month = jul, year = {2021}, note = {Presented at the ``Uncertainty and Robustness in Deep Learning (UDL)'' workshop at the 2021 Int.\ Conf.\ on Machine Learning (ICML)}, }
technical reports
-
 Robots and the Future of Welfare Services: A Finnish RoadmapVille Kyrki, Iina Aaltonen, Antti Ainasoja, Päivi Heikkilä, Sari Heikkinen, and 31 more authorsJul 2021
Robots and the Future of Welfare Services: A Finnish RoadmapVille Kyrki, Iina Aaltonen, Antti Ainasoja, Päivi Heikkilä, Sari Heikkinen, and 31 more authorsJul 2021This roadmap summarises a six-year multidisciplinary research project called Robots and the Future of Welfare Services (ROSE), funded by the Strategic Research Council (SRC) established within the Academy of Finland. The objective of the project was to study the current and expected technical opportunities and applications of robotics in welfare services, particularly in care services for older people. The research was carried out at three levels: individual, organisational and societal. The roadmap provides highlights of the various research activities of ROSE. We have studied the perspectives of older adults and care professionals as users of robots, how care organisations are able to adopt and utilise robots in their services, how technology companies find robots as business opportunity, and how the care robotics innovation ecosystem is evolving. Based on these and other studies, we evaluate the development and use of robots in care for older adults in terms of social, ethical-philosophical and political impacts as well as the public discussion on care robots. It appears that there are many single- or limited-purpose robot applications already commercially available in care services for older adults. To be widely adopted, robots should still increase maturity to be able to meet the requirements of care environments, such as in terms of their ability to move in smaller crowded spaces, easy and natural user interaction, and task flexibility. The roadmap provides visions of what could be technically expected in five and ten years. However, at the same time, organisations’ capabilities of adopting new technology and integrating it into services should be supported for them to be able to realise the potential of robots for the benefits of care workers and older persons, as well as the whole society. This roadmap also provides insight into the wider impacts and risks of robotization in society and how to steer it in a responsible way, presented as eight policy recommendations. We also discuss the ROSE project research as a multidisciplinary activity and present lessons learnt.
@techreport{202100_kyrki_robots, title = {Robots and the {Future} of {Welfare} {Services}: {A} {Finnish} {Roadmap}}, shorttitle = {Robots and the {Future} of {Welfare} {Services}}, number = {4}, institution = {Aalto University}, author = {Kyrki, Ville and Aaltonen, Iina and Ainasoja, Antti and Heikkilä, Päivi and Heikkinen, Sari and Hennala, Lea and Koistinen, Pertti and Kämäräinen, Joni and Laakso, Kalle and Laitinen, Arto and Lammi, Hanna and Lanne, Marinka and Lappalainen, Inka and Lehtinen, Hannu and Lehto, Paula and Leppälahti, Teppo and Lundell, Jens and Melkas, Helinä and Niemelä, Marketta and Parjanen, Satu and Parviainen, Jaana and Pekkarinen, Satu and Pirhonen, Jari and Porokuokka, Jaakko and Rantanen, Teemu and Ruohomäki, Ismo and Saurio, Riika and Sahlgren, Otto and Särkikoski, Tuomo and Talja, Heli and Tammela, Antti and Tuisku, Outi and Turja, Tuuli and Aerschot, Lina Van and Verdoja, Francesco and Välimäki, Kari}, year = {2021}, pages = {72}, }
2020
journal articles
- MVAP
 Graph Laplacian for image anomaly detectionFrancesco Verdoja and Marco GrangettoMachine Vision and Applications, Jan 2020
Graph Laplacian for image anomaly detectionFrancesco Verdoja and Marco GrangettoMachine Vision and Applications, Jan 2020Reed-Xiaoli detector (RXD) is recognized as the benchmark algorithm for image anomaly detection; however, it presents known limitations, namely the dependence over the image following a multivariate Gaussian model, the estimation and inversion of a high-dimensional covariance matrix, and the inability to effectively include spatial awareness in its evaluation. In this work, a novel graph-based solution to the image anomaly detection problem is proposed; leveraging the graph Fourier transform, we are able to overcome some of RXD’s limitations while reducing computational cost at the same time. Tests over both hyperspectral and medical images, using both synthetic and real anomalies, prove the proposed technique is able to obtain significant gains over performance by other algorithms in the state of the art.
@article{202001_verdoja_graph, title = {Graph {Laplacian} for image anomaly detection}, volume = {31}, issue = {1}, doi = {10.1007/s00138-020-01059-4}, number = {11}, journal = {Machine Vision and Applications}, author = {Verdoja, Francesco and Grangetto, Marco}, month = jan, year = {2020}, }
conference articles
- MFI
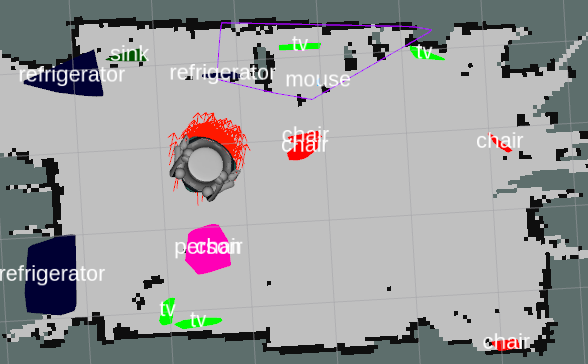 Hypermap Mapping Framework and its Application to Autonomous Semantic ExplorationTobias Zaenker, Francesco Verdoja, and Ville KyrkiIn 2020 IEEE Int. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), Sep 2020
Hypermap Mapping Framework and its Application to Autonomous Semantic ExplorationTobias Zaenker, Francesco Verdoja, and Ville KyrkiIn 2020 IEEE Int. Conf. on Multisensor Fusion and Integration for Intelligent Systems (MFI), Sep 2020Modern intelligent and autonomous robotic applications often require robots to have more information about their environment than that provided by traditional occupancy grid maps. For example, a robot tasked to perform autonomous semantic exploration has to label objects in the environment it is traversing while autonomously navigating. To solve this task the robot needs to at least maintain an occupancy map of the environment for navigation, an exploration map keeping track of which areas have already been visited, and a semantic map where locations and labels of objects in the environment are recorded. As the number of maps required grows, an application has to know and handle different map representations, which can be a burden.We present the Hypermap framework, which can manage multiple maps of different types. In this work, we explore the capabilities of the framework to handle occupancy grid layers and semantic polygonal layers, but the framework can be extended with new layer types in the future. Additionally, we present an algorithm to automatically generate semantic layers from RGB-D images. We demonstrate the utility of the framework using the example of autonomous exploration for semantic mapping.
@inproceedings{202009_zaenker_hypermap, title = {Hypermap {Mapping} {Framework} and its {Application} to {Autonomous} {Semantic} {Exploration}}, doi = {10.1109/MFI49285.2020.9235231}, booktitle = {2020 {IEEE} {Int.} {Conf.} on {Multisensor} {Fusion} and {Integration} for {Intelligent} {Systems} ({MFI})}, publisher = {IEEE}, author = {Zaenker, Tobias and Verdoja, Francesco and Kyrki, Ville}, month = sep, year = {2020}, pages = {133--139}, } - ICRA
 Beyond Top-Grasps Through Scene CompletionJens Lundell, Francesco Verdoja, and Ville KyrkiIn 2020 IEEE Int. Conf. on Robotics and Automation (ICRA), May 2020
Beyond Top-Grasps Through Scene CompletionJens Lundell, Francesco Verdoja, and Ville KyrkiIn 2020 IEEE Int. Conf. on Robotics and Automation (ICRA), May 2020Current end-to-end grasp planning methods propose grasps in the order of seconds that attain high grasp success rates on a diverse set of objects, but often by constraining the workspace to top-grasps. In this work, we present a method that allows end-to-end top-grasp planning methods to generate full six-degree-of-freedom grasps using a single RGBD view as input. This is achieved by estimating the complete shape of the object to be grasped, then simulating different viewpoints of the object, passing the simulated viewpoints to an end-to-end grasp generation method, and finally executing the overall best grasp. The method was experimentally validated on a Franka Emika Panda by comparing 429 grasps generated by the state-of-the-art Fully Convolutional Grasp Quality CNN, both on simulated and real camera images. The results show statistically significant improvements in terms of grasp success rate when using simulated images over real camera images, especially when the real camera viewpoint is angled.
@inproceedings{202005_lundell_beyond, title = {Beyond {Top}-{Grasps} {Through} {Scene} {Completion}}, doi = {10.1109/ICRA40945.2020.9197320}, booktitle = {2020 {IEEE} {Int.} {Conf.} on {Robotics} and {Automation} ({ICRA})}, publisher = {IEEE}, author = {Lundell, Jens and Verdoja, Francesco and Kyrki, Ville}, month = may, year = {2020}, pages = {545--551}, }
workshop articles
- ICRA
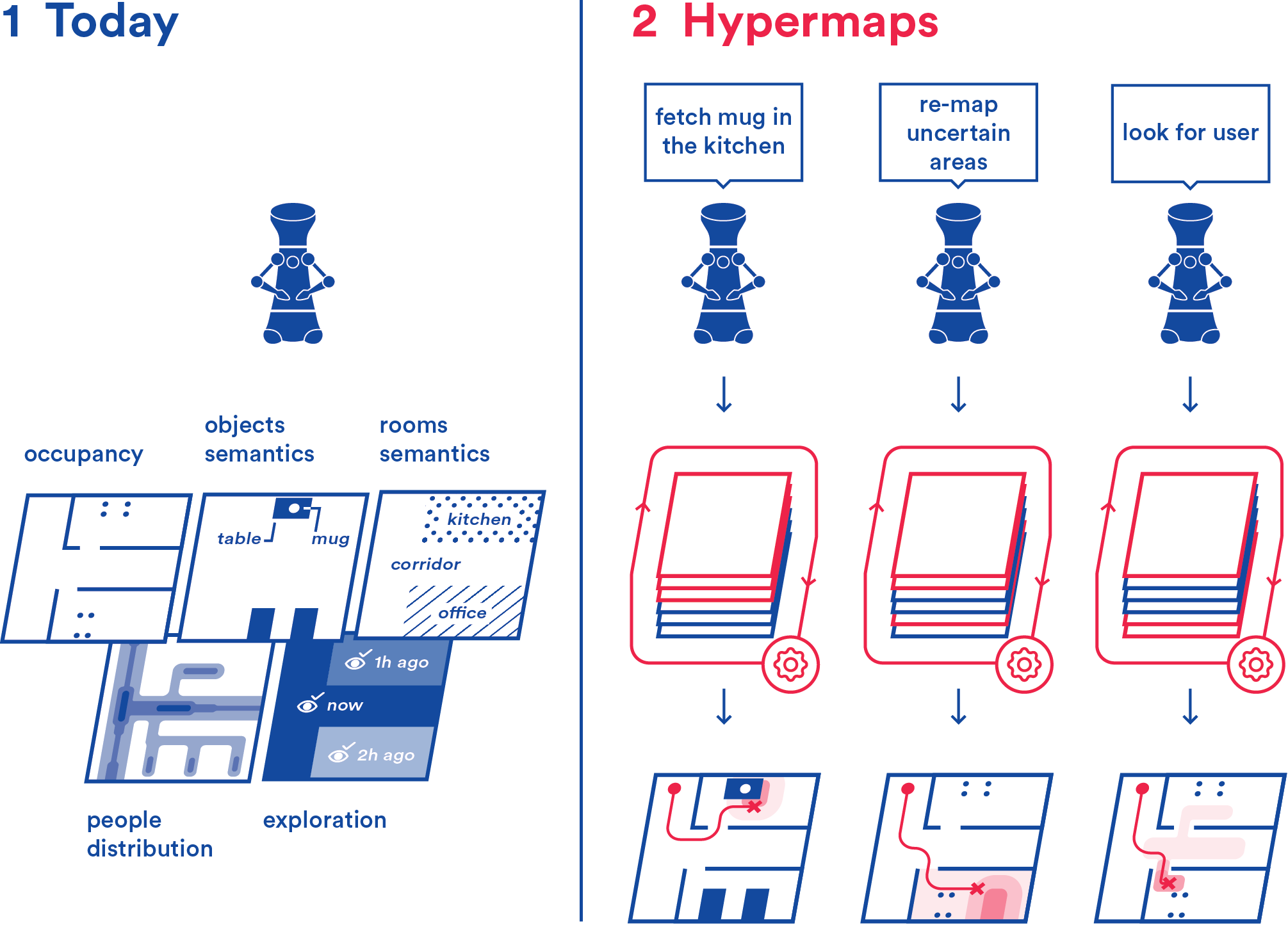 On the Potential of Smarter Multi-layer MapsFrancesco Verdoja and Ville KyrkiMay 2020Presented at the “Perception, Action, Learning (PAL)” workshop at the 2020 IEEE Int. Conf. on Robotics and Automation (ICRA)
On the Potential of Smarter Multi-layer MapsFrancesco Verdoja and Ville KyrkiMay 2020Presented at the “Perception, Action, Learning (PAL)” workshop at the 2020 IEEE Int. Conf. on Robotics and Automation (ICRA)The most common way for robots to handle environmental information is by using maps. At present, each kind of data is hosted on a separate map, which complicates planning because a robot attempting to perform a task needs to access and process information from many different maps. Also, most often correlation among the information contained in maps obtained from different sources is not evaluated or exploited. In this paper, we argue that in robotics a shift from single-source maps to a multi-layer mapping formalism has the potential to revolutionize the way robots interact with knowledge about their environment. This observation stems from the raise in metric-semantic mapping research, but expands to include in its formulation also layers containing other information sources, e.g., people flow, room semantic, or environment topology. Such multi-layer maps, here named hypermaps, not only can ease processing spatial data information but they can bring added benefits arising from the interaction between maps. We imagine that a new research direction grounded in such multi-layer mapping formalism for robots can use artificial intelligence to process the information it stores to present to the robot task-specific information simplifying planning and bringing us one step closer to high-level reasoning in robots.
@online{202005_verdoja_potential, title = {On the {Potential} of {Smarter} {Multi}-layer {Maps}}, url = {https://mit-spark.github.io/PAL-ICRA2020}, author = {Verdoja, Francesco and Kyrki, Ville}, month = may, year = {2020}, note = {Presented at the ``Perception, Action, Learning (PAL)'' workshop at the 2020 IEEE Int.\ Conf.\ on Robotics and Automation (ICRA)}, }
2019
conference articles
- IROS
 Robust Grasp Planning Over Uncertain Shape CompletionsJens Lundell, Francesco Verdoja, and Ville KyrkiIn 2019 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Nov 2019
Robust Grasp Planning Over Uncertain Shape CompletionsJens Lundell, Francesco Verdoja, and Ville KyrkiIn 2019 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Nov 2019We present a method for planning robust grasps over uncertain shape completed objects. For shape completion, a deep neural network is trained to take a partial view of the object as input and outputs the completed shape as a voxel grid. The key part of the network is dropout layers which are enabled not only during training but also at run-time to generate a set of shape samples representing the shape uncertainty through Monte Carlo sampling. Given the set of shape completed objects, we generate grasp candidates on the mean object shape but evaluate them based on their joint performance in terms of analytical grasp metrics on all the shape candidates. We experimentally validate and benchmark our method against another state-of-the-art method with a Barrett hand on 90000 grasps in simulation and 200 grasps on a real Franka Emika Panda. All experimental results show statistically significant improvements both in terms of grasp quality metrics and grasp success rate, demonstrating that planning shape-uncertainty-aware grasps brings significant advantages over solely planning on a single shape estimate, especially when dealing with complex or unknown objects.
@inproceedings{201911_lundell_robust, address = {Macau, China}, title = {Robust {Grasp} {Planning} {Over} {Uncertain} {Shape} {Completions}}, doi = {10.1109/IROS40897.2019.8967816}, booktitle = {2019 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Lundell, Jens and Verdoja, Francesco and Kyrki, Ville}, month = nov, year = {2019}, pages = {1526--1532}, } - Humanoids
 Deep Network Uncertainty Maps for Indoor NavigationFrancesco Verdoja, Jens Lundell, and Ville KyrkiIn 2019 IEEE-RAS Int. Conf. on Humanoid Robots (Humanoids), Oct 2019
Deep Network Uncertainty Maps for Indoor NavigationFrancesco Verdoja, Jens Lundell, and Ville KyrkiIn 2019 IEEE-RAS Int. Conf. on Humanoid Robots (Humanoids), Oct 2019Most mobile robots for indoor use rely on 2D laser scanners for localization, mapping and navigation. These sensors, however, cannot detect transparent surfaces or measure the full occupancy of complex objects such as tables. Deep Neural Networks have recently been proposed to overcome this limitation by learning to estimate object occupancy. These estimates are nevertheless subject to uncertainty, making the evaluation of their confidence an important issue for these measures to be useful for autonomous navigation and mapping. In this work we approach the problem from two sides. First we discuss uncertainty estimation in deep models, proposing a solution based on a fully convolutional neural network. The proposed architecture is not restricted by the assumption that the uncertainty follows a Gaussian model, as in the case of many popular solutions for deep model uncertainty estimation, such as Monte-Carlo Dropout. We present results showing that uncertainty over obstacle distances is actually better modeled with a Laplace distribution. Then, we propose a novel approach to build maps based on Deep Neural Network uncertainty models. In particular, we present an algorithm to build a map that includes information over obstacle distance estimates while taking into account the level of uncertainty in each estimate. We show how the constructed map can be used to increase global navigation safety by planning trajectories which avoid areas of high uncertainty, enabling higher autonomy for mobile robots in indoor settings.
@inproceedings{201910_verdoja_deep, address = {Toronto, Canada}, title = {Deep {Network} {Uncertainty} {Maps} for {Indoor} {Navigation}}, doi = {10.1109/Humanoids43949.2019.9035016}, booktitle = {2019 {IEEE-RAS} {Int.}\ {Conf.}\ on {Humanoid} {Robots} ({Humanoids})}, publisher = {IEEE}, author = {Verdoja, Francesco and Lundell, Jens and Kyrki, Ville}, month = oct, year = {2019}, pages = {112--119}, }
2018
conference articles
- IROS
 Hallucinating robots: Inferring obstacle distances from partial laser measurementsJens Lundell, Francesco Verdoja, and Ville KyrkiIn 2018 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2018
Hallucinating robots: Inferring obstacle distances from partial laser measurementsJens Lundell, Francesco Verdoja, and Ville KyrkiIn 2018 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2018Many mobile robots rely on 2D laser scanners for localization, mapping, and navigation. However, those sensors are unable to correctly provide distance to obstacles such as glass panels and tables whose actual occupancy is invisible at the height the sensor is measuring. In this work, instead of estimating the distance to obstacles from richer sensor readings such as 3D lasers or RGBD sensors, we present a method to estimate the distance directly from raw 2D laser data. To learn a mapping from raw 2D laser distances to obstacle distances we frame the problem as a learning task and train a neural network formed as an autoencoder. A novel configuration of network hyperparameters is proposed for the task at hand and is quantitatively validated on a test set. Finally, we qualitatively demonstrate in real time on a Care-O-bot 4 that the trained network can successfully infer obstacle distances from partial 2D laser readings.
@inproceedings{201810_lundell_hallucinating, address = {Madrid, Spain}, title = {Hallucinating robots: {Inferring} obstacle distances from partial laser measurements}, doi = {10.1109/IROS.2018.8594399}, booktitle = {2018 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots} and {Systems} ({IROS})}, publisher = {IEEE}, author = {Lundell, Jens and Verdoja, Francesco and Kyrki, Ville}, month = oct, year = {2018}, pages = {4781--4787}, }
patents
-
 Method and Apparatus for Encoding and Decoding Digital Images or Video StreamsMarco Grangetto and Francesco VerdojaSep 2018
Method and Apparatus for Encoding and Decoding Digital Images or Video StreamsMarco Grangetto and Francesco VerdojaSep 2018A method for encoding digital images or video streams, includes a receiving phase, wherein a portion of an image is received; a graph weights prediction phase, wherein the elements of a weights matrix associated to the graph related to the blocks of the image (predicted blocks) are predicted on the basis of reconstructed, de-quantized and inverse-transformed pixel values of at least one previously coded block (predictor block) of the image, the weights matrix being a matrix comprising elements denoting the level of similarity between a pair of pixels composing said image, a graph transform computation phase, wherein the graph Fourier transform of the blocks of the image is performed, obtaining for the blocks a set of coefficients determined on the basis of the predicted weights; a coefficients quantization phase, wherein the coefficients are quantized an output phase wherein a bitstream comprising the transformed and quantized coefficients is transmitted and/or stored.
@patent{201809_grangetto_method, title = {Method and {Apparatus} for {Encoding} and {Decoding} {Digital} {Images} or {Video} {Streams}}, assignee = {Sisvel Technology S.r.l}, number = {WO2018158735 (A1)}, author = {Grangetto, Marco and Verdoja, Francesco}, month = sep, year = {2018}, } -
 Methods and Apparatuses for Encoding and Decoding Superpixel BordersMarco Grangetto and Francesco VerdojaSep 2018
Methods and Apparatuses for Encoding and Decoding Superpixel BordersMarco Grangetto and Francesco VerdojaSep 2018The present invention relates to a method for encoding the borders of pixel regions of an image, wherein the borders contain a sequence of vertices subdividing the image into regions of pixels (superpixels), by generating a sequence of symbols from an alphabet including the step of: defining for each superpixel a first vertex for coding the borders of the superpixel according to a criterion common to all superpixels; defining for each superpixel the same coding order of the border vertices, either clockwise or counter-clockwise; defining the order for coding the superpixels on the base of a common rule depending on the relative positions of the first vertices; defining a set of vertices as a known border, wherein the following steps are performed for selecting a symbol of the alphabet, for encoding the borders of the superpixels: a) determining the first vertex of the next superpixel border individuated by the common criterion; b) determining the next vertex to be encoded on the basis of the coding direction; c) selecting a first symbol (“0”) for encoding the next vertex if the next vertex of a border pertains to the known border, d) selecting a symbol (“1”; “2”) different from the first symbol (“0”) if the next vertex is not in the known border; e) repeating steps b), c), d) and e) until all vertices of the superpixel border have been encoded; f) adding each vertex of the superpixel border that was not in the known border to the set; g) determining the next superpixel whose border is to be encoded according to the common rule, if any; i) repeating steps a)-g) until the borders of all the superpixels of the image have being added to the known border.
@patent{201809_grangetto_methods, title = {Methods and {Apparatuses} for {Encoding} and {Decoding} {Superpixel} {Borders}}, assignee = {Sisvel Technology S.r.l}, number = {WO2018158738 (A1)}, author = {Grangetto, Marco and Verdoja, Francesco}, month = sep, year = {2018}, }
2017
theses
-
 The use of Graph Fourier Transform in image processing: a new solution to classical problemsFrancesco VerdojaJul 2017
The use of Graph Fourier Transform in image processing: a new solution to classical problemsFrancesco VerdojaJul 2017Graph-based approaches have recently seen a spike of interest in the image processing and computer vision communities, and many classical problems are finding new solutions thanks to these techniques. The Graph Fourier Transform (GFT), the equivalent of the Fourier transform for graph signals, is used in many domains to analyze and process data modeled by a graph. In this thesis we present some classical image processing problems that can be solved through the use of GFT. We’ll focus our attention on two main research area: the first is image compression, where the use of the GFT is finding its way in recent literature; we’ll propose two novel ways to deal with the problem of graph weight encoding. We’ll also propose approaches to reduce overhead costs of shape-adaptive compression methods. The second research field is image anomaly detection, GFT has never been proposed to this date to solve this class of problems; we’ll discuss here a novel technique and we’ll test its application on hyperspectral and medical images. We’ll show how graph approaches can be used to generalize and improve performance of the widely popular RX Detector, by reducing its computational complexity while at the same time fixing the well known problem of its dependency from covariance matrix estimation and inversion. All our experiments confirm that graph-based approaches leveraging on the GFT can be a viable option to solve tasks in multiple image processing domains.
@phdthesis{201707_verdoja_use, address = {Torino, Italy}, type = {Doctoral dissertation}, title = {The use of {Graph} {Fourier} {Transform} in image processing: a new solution to classical problems}, shorttitle = {The use of {Graph} {Fourier} {Transform} in image processing}, school = {Università degli Studi di Torino}, author = {Verdoja, Francesco}, month = jul, year = {2017}, }
conference articles
- ICME
 Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understandingFrancesco Verdoja, Diego Thomas, and Akihiro SugimotoIn 2017 IEEE Int. Conf. on Multimedia and Expo (ICME), Jul 2017
Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understandingFrancesco Verdoja, Diego Thomas, and Akihiro SugimotoIn 2017 IEEE Int. Conf. on Multimedia and Expo (ICME), Jul 2017Segmentation of 3D colored point clouds is a research field with renewed interest thanks to recent availability of inexpensive consumer RGB-D cameras and its importance as an unavoidable low-level step in many robotic applications. However, 3D data’s nature makes the task challenging and, thus, many different techniques are being proposed , all of which require expensive computational costs. This paper presents a novel fast method for 3D colored point cloud segmen-tation. It starts with supervoxel partitioning of the cloud, i.e., an oversegmentation of the points in the cloud. Then it leverages on a novel metric exploiting both geometry and color to iteratively merge the supervoxels to obtain a 3D segmentation where the hierarchical structure of partitions is maintained. The algorithm also presents computational complexity linear to the size of the input. Experimental results over two publicly available datasets demonstrate that our proposed method outperforms state-of-the-art techniques.
@inproceedings{201707_verdoja_fast, address = {Hong Kong}, title = {Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understanding}, doi = {10.1109/ICME.2017.8019382}, booktitle = {2017 {IEEE} {Int.}\ {Conf.}\ on {Multimedia} and {Expo} ({ICME})}, publisher = {IEEE}, author = {Verdoja, Francesco and Thomas, Diego and Sugimoto, Akihiro}, month = jul, year = {2017}, pages = {1285--1290}, } - ICASSP
 Directional graph weight prediction for image compressionFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017
Directional graph weight prediction for image compressionFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017Graph-based models have recently attracted attention for their potential to enhance transform coding image compression thanks to their capability to efficiently represent discontinuities. Graph transform gets closer to the optimal KLT by using weights that represent inter-pixel correlations but the extra cost to provide such weights can overwhelm the gain, especially in the case of natural images rich of details. In this paper we provide a novel idea to make graph transform adaptive to the actual image content, avoiding the need to encode the graph weights as side information. We show that an approach similar to spatial prediction can be used to effectively predict graph weights in place of pixels; in particular, we propose the design of directional graph weight prediction modes and show the resulting coding gain. The proposed approach can be used jointly with other graph based intra prediction methods to further enhance compression. Our comparative experimental analysis, carried out with a fully fledged still image coding prototype, shows that we are able to achieve significant coding gains.
@inproceedings{201703_verdoja_directional, address = {New Orleans, LA}, title = {Directional graph weight prediction for image compression}, doi = {10.1109/ICASSP.2017.7952410}, booktitle = {2017 {IEEE} {Int.}\ {Conf.}\ on {Acoustics}, {Speech} and {Signal} {Processing} ({ICASSP})}, publisher = {IEEE}, author = {Verdoja, Francesco and Grangetto, Marco}, month = mar, year = {2017}, pages = {1517--1521}, } - ICASSP
 Efficient representation of segmentation contours using chain codesFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017
Efficient representation of segmentation contours using chain codesFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017Segmentation is one of the most important low-level tasks in image processing as it enables many higher level computer vision tasks like object recognition and tracking. Segmentation can also be exploited for image compression using recent graph-based algorithms, provided that the corresponding contours can be represented efficiently. Transmission of borders is also key to distributed computer vision. In this paper we propose a new chain code tailored to compress segmentation contours. Based on the widely known 3OT, our algorithm is able to encode regions avoiding borders it has already coded once and without the need of any starting point information for each region. We tested our method against three other state of the art chain codes over the BSDS500 dataset, and we demonstrated that the proposed chain code achieves the highest compression ratio, resulting on average in over 27% bit-per-pixel saving.
@inproceedings{201703_verdoja_efficient, address = {New Orleans, LA}, title = {Efficient representation of segmentation contours using chain codes}, doi = {10.1109/ICASSP.2017.7952399}, booktitle = {2017 {IEEE} {Int.}\ {Conf.}\ on {Acoustics}, {Speech} and {Signal} {Processing} ({ICASSP})}, publisher = {IEEE}, author = {Verdoja, Francesco and Grangetto, Marco}, month = mar, year = {2017}, pages = {1462--1466}, }
patents
-
 Methods and Apparatuses for Encoding and Decoding Digital Images Through SuperpixelsGiulia Fracastoro, Enrico Magli, Francesco Verdoja, and Marco GrangettoMar 2017
Methods and Apparatuses for Encoding and Decoding Digital Images Through SuperpixelsGiulia Fracastoro, Enrico Magli, Francesco Verdoja, and Marco GrangettoMar 2017A method and an apparatus for encoding and/or decoding digital images or video streams are provided, wherein the encoding apparatus includes a processor configured for reading at least a portion of the image, segmenting the portion of the image in order to obtain groups of pixels identified by borders information and containing at least two pixels having one or more homogeneous characteristics, computing, for each group of pixels, a weight map on the basis of the borders information associated to the group of pixels, a graph transform matrix on the basis of the weight map, and transform coefficients on the basis of the graph transform matrix (U) and of the pixels contained in the group of pixels.
@patent{201703_fracastoro_methods, title = {Methods and {Apparatuses} for {Encoding} and {Decoding} {Digital} {Images} {Through} {Superpixels}}, assignee = {Sisvel Technology Srl; Politecnico Di Torino}, number = {WO2017051358 (A1)}, author = {Fracastoro, Giulia and Magli, Enrico and Verdoja, Francesco and Grangetto, Marco}, month = mar, year = {2017}, }
2016
book chapters
- AIFM
 Automatic GTV contouring applying anomaly detection algorithm on dynamic FDG PET imagesChristian Bracco, Francesco Verdoja, Marco Grangetto, Amalia Di Dia, Manuela Racca, and 2 more authorsIn Abstracts of the 9th National Congress of the Associazione Italiana di Fisica Medica, Feb 2016
Automatic GTV contouring applying anomaly detection algorithm on dynamic FDG PET imagesChristian Bracco, Francesco Verdoja, Marco Grangetto, Amalia Di Dia, Manuela Racca, and 2 more authorsIn Abstracts of the 9th National Congress of the Associazione Italiana di Fisica Medica, Feb 2016Introduction: The aim of this work is to show the results of GTV automatic segmentation based on dynamic PET acquisition. With respect to single voxel segmentation the temporal information is used to improve quality of GTV delineation. The segmentation algorithm proposed exploits the theoretic assumption that FDG uptake over time in cancer cells is very different from the one in normal tissues and therefore in this study anomaly detection is used to look for tumor peculiar-anomalous TACs. Material and Methods: For each patient two list mode datasets of images were acquired. The first one scan (basal) was acquired one hour after FDG injection and reconstructed as static frame. The last one (delayed) was acquired half one hour after the first scan and reconstructed as dynamic scan. Two delayed scans were registered to the basal scan. A modified version of the RX Detector was used. RX Detector usually works in RGB, but in this study its use on TACs has been explored passing the three grayscale images in place of the three channels of RGB. The resulting single image, which actually is a matrix of Mahalanobis distances, presents values that are very high for voxels whose TAC has anomalous temporal behavior. Finally, threshold segmentation is performed on the distance matrix. On a dataset of 10 patients segmentation techniques present in the literature working on single PET scan have been implemented as well as segmentation techniques based on RX Detector output. Results: Spatial overlap index (SOI) was used as metric to evaluate the segmentation accuracy. All of the segmentation algorithms implemented on RXD output show better SOI (0.507 ± 0.158) than algorithm based on SUV, i.e. Brambilla, SOI 0.278 ± 0.236. A manual contour drawn by experienced Nuclear Physician was the reference. Conclusion: Although a small dataset, the segmentation of dynamic PET images based on RXD output seems to be promising.
@incollection{201602_bracco_automatic, series = {Physica Medica}, title = {Automatic {GTV} contouring applying anomaly detection algorithm on dynamic {FDG} {PET} images}, number = {1}, volume = {32}, doi = {10.1016/j.ejmp.2016.01.343}, booktitle = {Abstracts of the 9th National Congress of the Associazione Italiana di Fisica Medica}, author = {Bracco, Christian and Verdoja, Francesco and Grangetto, Marco and Di Dia, Amalia and Racca, Manuela and Varetto, Teresio and Stasi, Michele}, month = feb, year = {2016}, pages = {99}, }
conference articles
- ICIP
 Global and local anomaly detectors for tumor segmentation in dynamic PET acquisitionsFrancesco Verdoja, Barbara Bonafè, Davide Cavagnino, Marco Grangetto, Christian Bracco, and 3 more authorsIn 2016 IEEE Int. Conf. on Image Processing (ICIP), Sep 2016
Global and local anomaly detectors for tumor segmentation in dynamic PET acquisitionsFrancesco Verdoja, Barbara Bonafè, Davide Cavagnino, Marco Grangetto, Christian Bracco, and 3 more authorsIn 2016 IEEE Int. Conf. on Image Processing (ICIP), Sep 2016In this paper we explore the application of anomaly detection techniques to tumor voxels segmentation. The developed algorithms work on 3-points dynamic FDG-PET acquisitions and leverage on the peculiar anaerobic metabolism that cancer cells experience over time. A few different global or local anomaly detectors are discussed, together with an investigation over two different algorithms aiming to estimate normal tissues’ statistical distribution. Finally, all the proposed algorithms are tested on a dataset composed of 9 patients proving that anomaly detectors are able to outperform techniques in the state of the art.
@inproceedings{201609_verdoja_global, address = {Phoenix, AZ}, title = {Global and local anomaly detectors for tumor segmentation in dynamic {PET} acquisitions}, doi = {10.1109/ICIP.2016.7533137}, booktitle = {2016 {IEEE} {Int.}\ {Conf.}\ on {Image} {Processing} ({ICIP})}, publisher = {IEEE}, author = {Verdoja, Francesco and Bonafè, Barbara and Cavagnino, Davide and Grangetto, Marco and Bracco, Christian and Varetto, Teresio and Racca, Manuela and Stasi, Michele}, month = sep, year = {2016}, pages = {4131--4135}, }
2015
book chapters
- ICIAP
 Fast Superpixel-Based Hierarchical Approach to Image SegmentationFrancesco Verdoja and Marco GrangettoIn Image Analysis and Processing—ICIAP 2015, Sep 2015
Fast Superpixel-Based Hierarchical Approach to Image SegmentationFrancesco Verdoja and Marco GrangettoIn Image Analysis and Processing—ICIAP 2015, Sep 2015Image segmentation is one of the core task in image processing. Traditionally such operation is performed starting from single pixels requiring a significant amount of computations. Only recently it has been shown that superpixels can be used to improve segmentation performance. In this work we propose a novel superpixel-based hierarchical approach for image segmentation that works by iteratively merging nodes of a weighted undirected graph initialized with the superpixels regions. Proper metrics to drive the regions merging are proposed and experimentally validated using the standard Berkeley Dataset. Our analysis shows that the proposed algorithm runs faster than state of the art techniques while providing accurate segmentation results both in terms of visual and objective metrics.
@incollection{201509_verdoja_fast, series = {Lecture {Notes} in {Computer} {Science}}, title = {Fast {Superpixel}-{Based} {Hierarchical} {Approach} to {Image} {Segmentation}}, number = {9279}, doi = {10.1007/978-3-319-23231-7_33}, booktitle = {Image {Analysis} and {Processing}---{ICIAP} 2015}, publisher = {Springer}, author = {Verdoja, Francesco and Grangetto, Marco}, month = sep, year = {2015}, pages = {364--374}, }
conference articles
- ICIP
 Superpixel-driven Graph Transform for Image CompressionGiulia Fracastoro, Francesco Verdoja, Marco Grangetto, and Enrico MagliIn 2015 IEEE Int. Conf. on Image Processing (ICIP), Sep 2015
Superpixel-driven Graph Transform for Image CompressionGiulia Fracastoro, Francesco Verdoja, Marco Grangetto, and Enrico MagliIn 2015 IEEE Int. Conf. on Image Processing (ICIP), Sep 2015Awarded at the 2015 IEEE Int. Conf. on Image Processing (ICIP)
Block-based compression tends to be inefficient when blocks contain arbitrary shaped discontinuities. Recently, graph-based approaches have been proposed to address this issue, but the cost of transmitting graph topology often overcome the gain of such techniques. In this work we propose a new Superpixel-driven Graph Transform (SDGT) that uses clusters of superpixels, which have the ability to adhere nicely to edges in the image, as coding blocks and computes inside these homogeneously colored regions a graph transform which is shape-adaptive. Doing so, only the borders of the regions and the transform coefficients need to be transmitted, in place of all the structure of the graph. The proposed method is finally compared to DCT and the experimental results show how it is able to outperform DCT both visually and in term of PSNR.
@inproceedings{201509_fracastoro_superpixel-driven, address = {Quebec City, Canada}, title = {Superpixel-driven {Graph} {Transform} for {Image} {Compression}}, doi = {10.1109/ICIP.2015.7351279}, booktitle = {2015 {IEEE} {Int.}\ {Conf.}\ on {Image} {Processing} ({ICIP})}, publisher = {IEEE}, author = {Fracastoro, Giulia and Verdoja, Francesco and Grangetto, Marco and Magli, Enrico}, month = sep, year = {2015}, pages = {2631--2635}, }
2014
conference articles
- ICIP
 Automatic method for tumor segmentation from 3-points dynamic PET acquisitionsFrancesco Verdoja, Marco Grangetto, Christian Bracco, Teresio Varetto, Manuela Racca, and 1 more authorIn 2014 IEEE Int. Conf. on Image Processing (ICIP), Oct 2014
Automatic method for tumor segmentation from 3-points dynamic PET acquisitionsFrancesco Verdoja, Marco Grangetto, Christian Bracco, Teresio Varetto, Manuela Racca, and 1 more authorIn 2014 IEEE Int. Conf. on Image Processing (ICIP), Oct 2014Awarded for this work by Microsoft Research Cambridge at the 2014 International Computer Vision Summer School (ICVSS)
In this paper a novel technique to segment tumor voxels in dynamic positron emission tomography (PET) scans is proposed. An innovative anomaly detection tool tailored for 3-points dynamic PET scans is designed. The algorithm allows the identification of tumoral cells in dynamic FDG-PET scans thanks to their peculiar anaerobic metabolism experienced over time. The proposed tool is preliminarily tested on a small dataset showing promising performance as compared to the state of the art in terms of both accuracy and classification errors.
@inproceedings{201410_verdoja_automatic, address = {Paris, France}, title = {Automatic method for tumor segmentation from 3-points dynamic {PET} acquisitions}, doi = {10.1109/ICIP.2014.7025188}, booktitle = {2014 {IEEE} {Int.}\ {Conf.}\ on {Image} {Processing} ({ICIP})}, publisher = {IEEE}, author = {Verdoja, Francesco and Grangetto, Marco and Bracco, Christian and Varetto, Teresio and Racca, Manuela and Stasi, Michele}, month = oct, year = {2014}, pages = {937--941}, }