Visual-language models (VLMs) have recently been introduced in robotic mapping using the latent representations, i.e., embeddings, of the VLMs to represent semantics in the map. They allow moving from a limited set of human-created labels toward open-vocabulary scene understanding, which is very useful for robots when operating in complex real-world environments and interacting with humans. While there is anecdotal evidence that maps built this way support downstream tasks, such as navigation, rigorous analysis of the quality of the maps using these embeddings is missing. In this paper, we propose a way to analyze the quality of maps created using VLMs. We investigate two critical properties of map quality: queryability and distinctness. The evaluation of queryability addresses the ability to retrieve information from the embeddings. We investigate intra-map distinctness to study the ability of the embeddings to represent abstract semantic classes and inter-map distinctness to evaluate the generalization properties of the representation. We propose metrics to evaluate these properties and evaluate two state-of-the-art mapping methods, VLMaps and OpenScene, using two encoders, LSeg and OpenSeg, using real-world data from the Matterport3D data set. Our findings show that while 3D features improve queryability, they are not scale invariant, whereas image-based embeddings generalize to multiple map resolutions. This allows the image-based methods to maintain smaller map sizes, which can be crucial for using these methods in real-world deployments. Furthermore, we show that the choice of the encoder has an effect on the results. The results imply that properly thresholding open-vocabulary queries is an open problem.
@inproceedings{202510_pekkanen_visual-language,address={Hangzhou, China},title={Do {Visual}-{Language} {Grid} {Maps} {Capture} {Latent}
{Semantics}?},doi={10.1109/IROS60139.2025.11247447},booktitle={2025 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots}
and {Systems} ({IROS})},publisher={IEEE},author={Pekkanen, Matti and Mihaylova, Tsvetomila and Verdoja, Francesco and Kyrki, Ville},month=oct,year={2025},pages={4059--4066},}
IROS
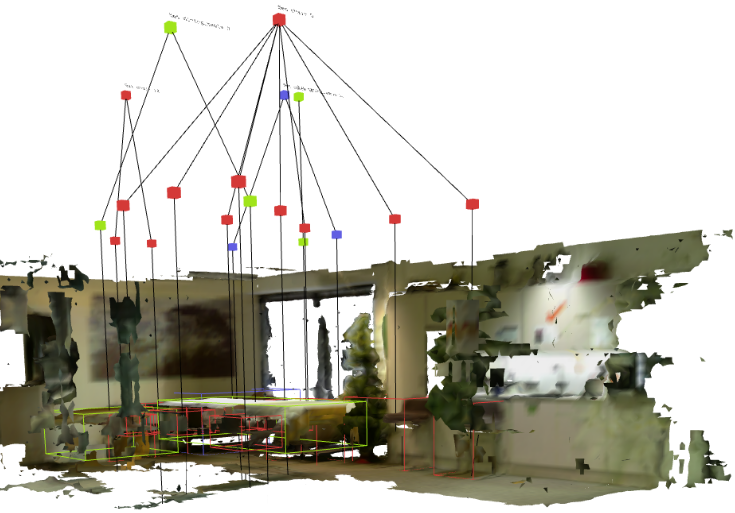
REACT: Real-time Efficient Attribute Clustering and Transfer for Updatable 3D Scene Graph
Phuoc Nguyen, Francesco Verdoja, and Ville Kyrki
In 2025 IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Oct 2025
Modern-day autonomous robots need high-level map representations to perform sophisticated tasks. Recently, 3D scene graphs (3DSGs) have emerged as a promising alternative to traditional grid maps, blending efficient memory use and rich feature representation. However, most efforts to apply them have been limited to static worlds. This work introduces REACT, a framework that efficiently performs real-time attribute clustering and transfer to relocalize object nodes in a 3DSG. REACT employs a novel method for comparing object instances using an embedding model trained on triplet loss, facilitating instance clustering and matching. Experimental results demonstrate that REACT is able to relocalize objects while maintaining computational efficiency. The REACT framework’s source code will be available as an open-source project, promoting further advancements in reusable and updatable 3DSGs.
@inproceedings{202510_nguyen_react,address={Hangzhou, China},title={{REACT}: {Real}-time {Efficient} {Attribute} {Clustering} and
{Transfer} for {Updatable} {3D} {Scene} {Graph}},shorttitle={{REACT}},doi={10.1109/IROS60139.2025.11247273},booktitle={2025 {IEEE}/{RSJ} {Int.}\ {Conf.}\ on {Intelligent} {Robots}
and {Systems} ({IROS})},publisher={IEEE},author={Nguyen, Phuoc and Verdoja, Francesco and Kyrki, Ville},month=oct,year={2025},pages={2209--2216},}