Ph.D. scholarship | Segmentation and tracking methods for innovative video compression techniques
3-year full Ph.D. scholarship
- Funded by: Sisvel Technology
- Budget: 41k€
- Period: Jan 2014–Dec 2016
abstract
The first phase of standardization of the brand new MPEG coding technology, HEVC, has just been completed. However, there is a significant need of new coding techniques that can satisfy the requirements of future video applications and services, e.g. ultra high definition and high frame rate content and fully immersive multimedia experiences. Innovative image segmentation and tracking tools are expected to play a significant role in the design of novel compression technologies in the era of ultra-high definition and high frame rate video content.
related publications
theses
-
 The use of Graph Fourier Transform in image processing: a new solution to classical problemsFrancesco VerdojaJul 2017
The use of Graph Fourier Transform in image processing: a new solution to classical problemsFrancesco VerdojaJul 2017Graph-based approaches have recently seen a spike of interest in the image processing and computer vision communities, and many classical problems are finding new solutions thanks to these techniques. The Graph Fourier Transform (GFT), the equivalent of the Fourier transform for graph signals, is used in many domains to analyze and process data modeled by a graph. In this thesis we present some classical image processing problems that can be solved through the use of GFT. We’ll focus our attention on two main research area: the first is image compression, where the use of the GFT is finding its way in recent literature; we’ll propose two novel ways to deal with the problem of graph weight encoding. We’ll also propose approaches to reduce overhead costs of shape-adaptive compression methods. The second research field is image anomaly detection, GFT has never been proposed to this date to solve this class of problems; we’ll discuss here a novel technique and we’ll test its application on hyperspectral and medical images. We’ll show how graph approaches can be used to generalize and improve performance of the widely popular RX Detector, by reducing its computational complexity while at the same time fixing the well known problem of its dependency from covariance matrix estimation and inversion. All our experiments confirm that graph-based approaches leveraging on the GFT can be a viable option to solve tasks in multiple image processing domains.
@phdthesis{201707_verdoja_use, address = {Torino, Italy}, type = {Doctoral dissertation}, title = {The use of {Graph} {Fourier} {Transform} in image processing: a new solution to classical problems}, shorttitle = {The use of {Graph} {Fourier} {Transform} in image processing}, school = {Università degli Studi di Torino}, author = {Verdoja, Francesco}, month = jul, year = {2017}, }
journal articles
- MVAP
 Graph Laplacian for image anomaly detectionFrancesco Verdoja and Marco GrangettoMachine Vision and Applications, Jan 2020
Graph Laplacian for image anomaly detectionFrancesco Verdoja and Marco GrangettoMachine Vision and Applications, Jan 2020Reed-Xiaoli detector (RXD) is recognized as the benchmark algorithm for image anomaly detection; however, it presents known limitations, namely the dependence over the image following a multivariate Gaussian model, the estimation and inversion of a high-dimensional covariance matrix, and the inability to effectively include spatial awareness in its evaluation. In this work, a novel graph-based solution to the image anomaly detection problem is proposed; leveraging the graph Fourier transform, we are able to overcome some of RXD’s limitations while reducing computational cost at the same time. Tests over both hyperspectral and medical images, using both synthetic and real anomalies, prove the proposed technique is able to obtain significant gains over performance by other algorithms in the state of the art.
@article{202001_verdoja_graph, title = {Graph {Laplacian} for image anomaly detection}, volume = {31}, issue = {1}, doi = {10.1007/s00138-020-01059-4}, number = {11}, journal = {Machine Vision and Applications}, author = {Verdoja, Francesco and Grangetto, Marco}, month = jan, year = {2020}, }
book chapters
- ICIAP
 Fast Superpixel-Based Hierarchical Approach to Image SegmentationFrancesco Verdoja and Marco GrangettoIn Image Analysis and Processing—ICIAP 2015, Sep 2015
Fast Superpixel-Based Hierarchical Approach to Image SegmentationFrancesco Verdoja and Marco GrangettoIn Image Analysis and Processing—ICIAP 2015, Sep 2015Image segmentation is one of the core task in image processing. Traditionally such operation is performed starting from single pixels requiring a significant amount of computations. Only recently it has been shown that superpixels can be used to improve segmentation performance. In this work we propose a novel superpixel-based hierarchical approach for image segmentation that works by iteratively merging nodes of a weighted undirected graph initialized with the superpixels regions. Proper metrics to drive the regions merging are proposed and experimentally validated using the standard Berkeley Dataset. Our analysis shows that the proposed algorithm runs faster than state of the art techniques while providing accurate segmentation results both in terms of visual and objective metrics.
@incollection{201509_verdoja_fast, series = {Lecture {Notes} in {Computer} {Science}}, title = {Fast {Superpixel}-{Based} {Hierarchical} {Approach} to {Image} {Segmentation}}, number = {9279}, doi = {10.1007/978-3-319-23231-7_33}, booktitle = {Image {Analysis} and {Processing}---{ICIAP} 2015}, publisher = {Springer}, author = {Verdoja, Francesco and Grangetto, Marco}, month = sep, year = {2015}, pages = {364--374}, }
conference articles
- ICME
 Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understandingFrancesco Verdoja, Diego Thomas, and Akihiro SugimotoIn 2017 IEEE Int. Conf. on Multimedia and Expo (ICME), Jul 2017
Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understandingFrancesco Verdoja, Diego Thomas, and Akihiro SugimotoIn 2017 IEEE Int. Conf. on Multimedia and Expo (ICME), Jul 2017Segmentation of 3D colored point clouds is a research field with renewed interest thanks to recent availability of inexpensive consumer RGB-D cameras and its importance as an unavoidable low-level step in many robotic applications. However, 3D data’s nature makes the task challenging and, thus, many different techniques are being proposed , all of which require expensive computational costs. This paper presents a novel fast method for 3D colored point cloud segmen-tation. It starts with supervoxel partitioning of the cloud, i.e., an oversegmentation of the points in the cloud. Then it leverages on a novel metric exploiting both geometry and color to iteratively merge the supervoxels to obtain a 3D segmentation where the hierarchical structure of partitions is maintained. The algorithm also presents computational complexity linear to the size of the input. Experimental results over two publicly available datasets demonstrate that our proposed method outperforms state-of-the-art techniques.
@inproceedings{201707_verdoja_fast, address = {Hong Kong}, title = {Fast 3D point cloud segmentation using supervoxels with geometry and color for 3D scene understanding}, doi = {10.1109/ICME.2017.8019382}, booktitle = {2017 {IEEE} {Int.}\ {Conf.}\ on {Multimedia} and {Expo} ({ICME})}, publisher = {IEEE}, author = {Verdoja, Francesco and Thomas, Diego and Sugimoto, Akihiro}, month = jul, year = {2017}, pages = {1285--1290}, } - ICASSP
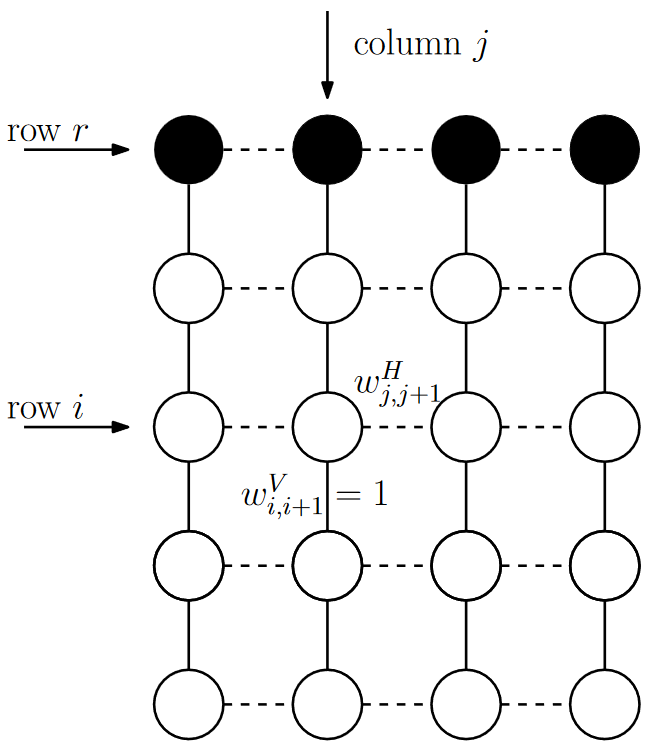 Directional graph weight prediction for image compressionFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017
Directional graph weight prediction for image compressionFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017Graph-based models have recently attracted attention for their potential to enhance transform coding image compression thanks to their capability to efficiently represent discontinuities. Graph transform gets closer to the optimal KLT by using weights that represent inter-pixel correlations but the extra cost to provide such weights can overwhelm the gain, especially in the case of natural images rich of details. In this paper we provide a novel idea to make graph transform adaptive to the actual image content, avoiding the need to encode the graph weights as side information. We show that an approach similar to spatial prediction can be used to effectively predict graph weights in place of pixels; in particular, we propose the design of directional graph weight prediction modes and show the resulting coding gain. The proposed approach can be used jointly with other graph based intra prediction methods to further enhance compression. Our comparative experimental analysis, carried out with a fully fledged still image coding prototype, shows that we are able to achieve significant coding gains.
@inproceedings{201703_verdoja_directional, address = {New Orleans, LA}, title = {Directional graph weight prediction for image compression}, doi = {10.1109/ICASSP.2017.7952410}, booktitle = {2017 {IEEE} {Int.}\ {Conf.}\ on {Acoustics}, {Speech} and {Signal} {Processing} ({ICASSP})}, publisher = {IEEE}, author = {Verdoja, Francesco and Grangetto, Marco}, month = mar, year = {2017}, pages = {1517--1521}, } - ICASSP
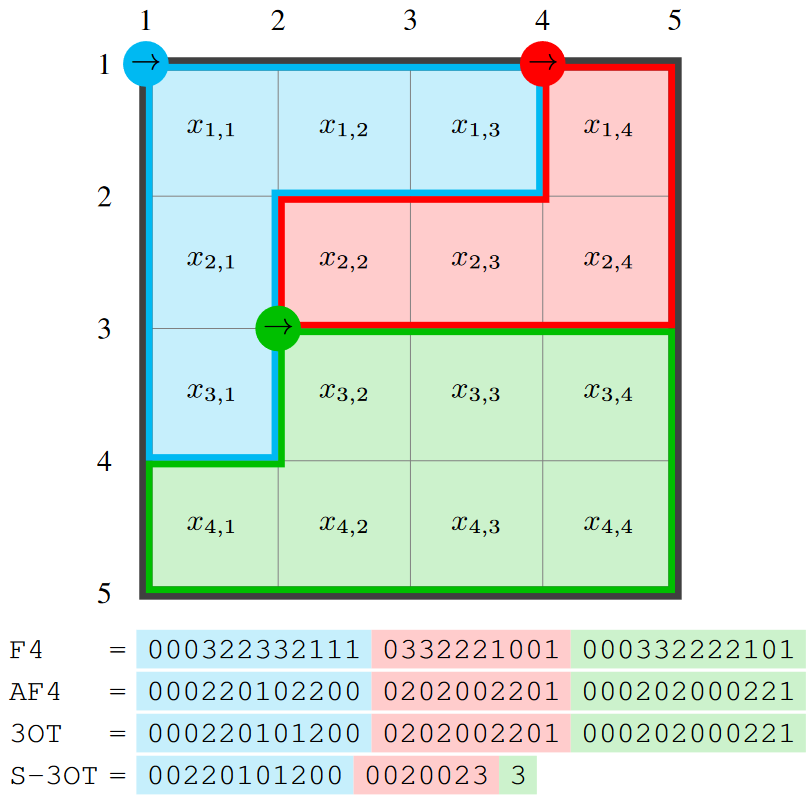 Efficient representation of segmentation contours using chain codesFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017
Efficient representation of segmentation contours using chain codesFrancesco Verdoja and Marco GrangettoIn 2017 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Mar 2017Segmentation is one of the most important low-level tasks in image processing as it enables many higher level computer vision tasks like object recognition and tracking. Segmentation can also be exploited for image compression using recent graph-based algorithms, provided that the corresponding contours can be represented efficiently. Transmission of borders is also key to distributed computer vision. In this paper we propose a new chain code tailored to compress segmentation contours. Based on the widely known 3OT, our algorithm is able to encode regions avoiding borders it has already coded once and without the need of any starting point information for each region. We tested our method against three other state of the art chain codes over the BSDS500 dataset, and we demonstrated that the proposed chain code achieves the highest compression ratio, resulting on average in over 27% bit-per-pixel saving.
@inproceedings{201703_verdoja_efficient, address = {New Orleans, LA}, title = {Efficient representation of segmentation contours using chain codes}, doi = {10.1109/ICASSP.2017.7952399}, booktitle = {2017 {IEEE} {Int.}\ {Conf.}\ on {Acoustics}, {Speech} and {Signal} {Processing} ({ICASSP})}, publisher = {IEEE}, author = {Verdoja, Francesco and Grangetto, Marco}, month = mar, year = {2017}, pages = {1462--1466}, } - ICIP
 Superpixel-driven Graph Transform for Image CompressionGiulia Fracastoro, Francesco Verdoja, Marco Grangetto, and Enrico MagliIn 2015 IEEE Int. Conf. on Image Processing (ICIP), Sep 2015
Superpixel-driven Graph Transform for Image CompressionGiulia Fracastoro, Francesco Verdoja, Marco Grangetto, and Enrico MagliIn 2015 IEEE Int. Conf. on Image Processing (ICIP), Sep 2015Awarded at the 2015 IEEE Int. Conf. on Image Processing (ICIP)
Block-based compression tends to be inefficient when blocks contain arbitrary shaped discontinuities. Recently, graph-based approaches have been proposed to address this issue, but the cost of transmitting graph topology often overcome the gain of such techniques. In this work we propose a new Superpixel-driven Graph Transform (SDGT) that uses clusters of superpixels, which have the ability to adhere nicely to edges in the image, as coding blocks and computes inside these homogeneously colored regions a graph transform which is shape-adaptive. Doing so, only the borders of the regions and the transform coefficients need to be transmitted, in place of all the structure of the graph. The proposed method is finally compared to DCT and the experimental results show how it is able to outperform DCT both visually and in term of PSNR.
@inproceedings{201509_fracastoro_superpixel-driven, address = {Quebec City, Canada}, title = {Superpixel-driven {Graph} {Transform} for {Image} {Compression}}, doi = {10.1109/ICIP.2015.7351279}, booktitle = {2015 {IEEE} {Int.}\ {Conf.}\ on {Image} {Processing} ({ICIP})}, publisher = {IEEE}, author = {Fracastoro, Giulia and Verdoja, Francesco and Grangetto, Marco and Magli, Enrico}, month = sep, year = {2015}, pages = {2631--2635}, }
patents
-
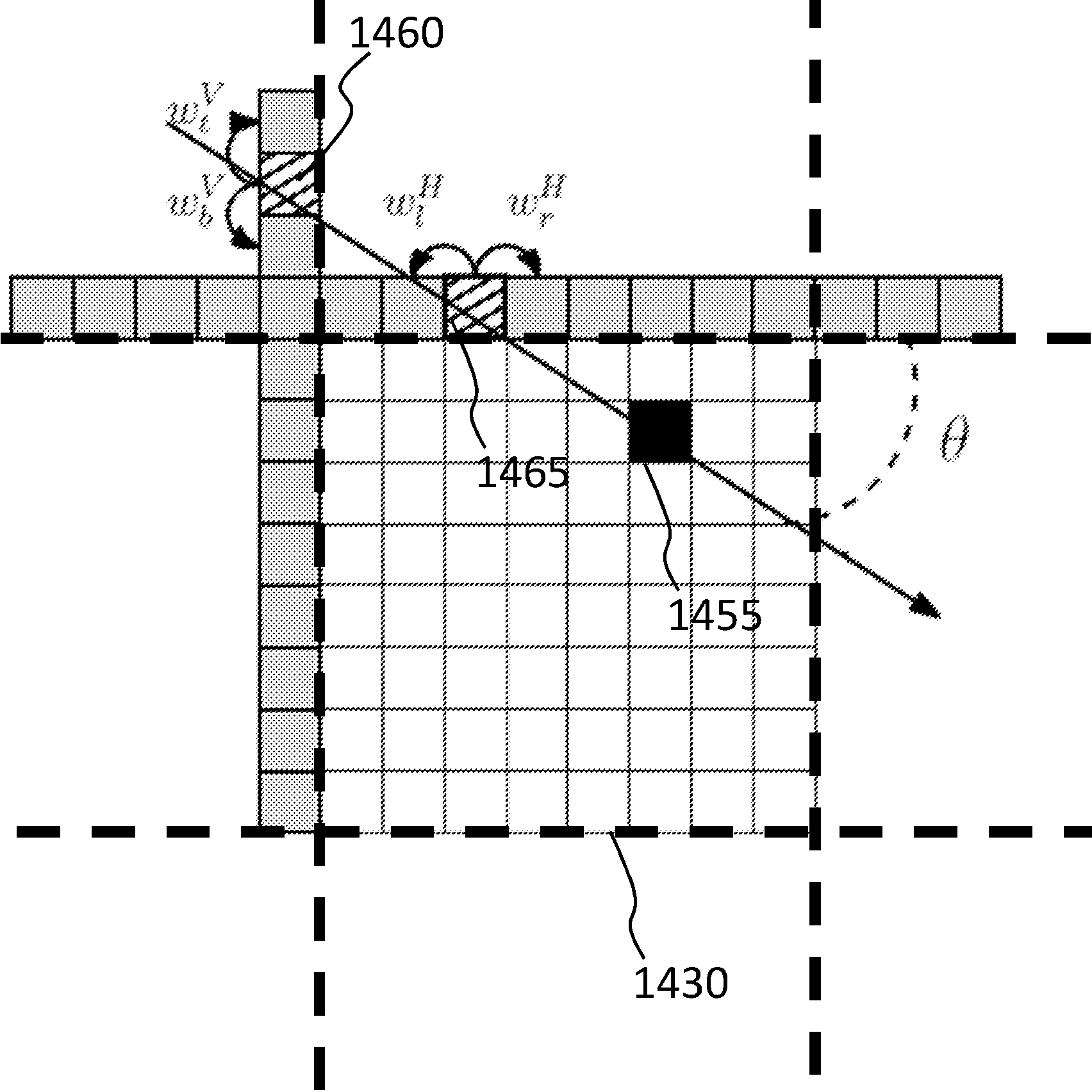 Method and Apparatus for Encoding and Decoding Digital Images or Video StreamsMarco Grangetto and Francesco VerdojaSep 2018
Method and Apparatus for Encoding and Decoding Digital Images or Video StreamsMarco Grangetto and Francesco VerdojaSep 2018A method for encoding digital images or video streams, includes a receiving phase, wherein a portion of an image is received; a graph weights prediction phase, wherein the elements of a weights matrix associated to the graph related to the blocks of the image (predicted blocks) are predicted on the basis of reconstructed, de-quantized and inverse-transformed pixel values of at least one previously coded block (predictor block) of the image, the weights matrix being a matrix comprising elements denoting the level of similarity between a pair of pixels composing said image, a graph transform computation phase, wherein the graph Fourier transform of the blocks of the image is performed, obtaining for the blocks a set of coefficients determined on the basis of the predicted weights; a coefficients quantization phase, wherein the coefficients are quantized an output phase wherein a bitstream comprising the transformed and quantized coefficients is transmitted and/or stored.
@patent{201809_grangetto_method, title = {Method and {Apparatus} for {Encoding} and {Decoding} {Digital} {Images} or {Video} {Streams}}, assignee = {Sisvel Technology S.r.l}, number = {WO2018158735 (A1)}, author = {Grangetto, Marco and Verdoja, Francesco}, month = sep, year = {2018}, } -
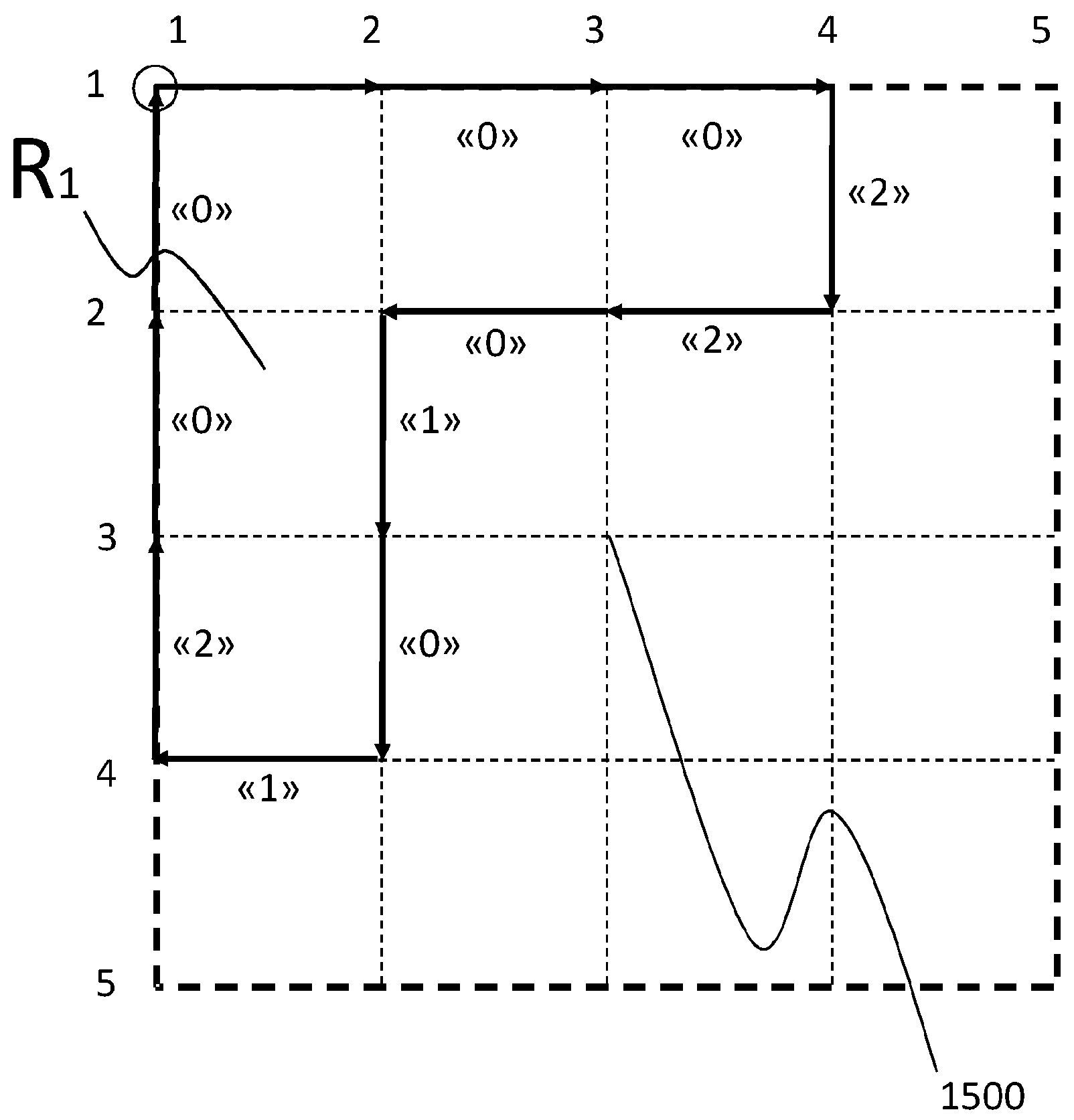 Methods and Apparatuses for Encoding and Decoding Superpixel BordersMarco Grangetto and Francesco VerdojaSep 2018
Methods and Apparatuses for Encoding and Decoding Superpixel BordersMarco Grangetto and Francesco VerdojaSep 2018The present invention relates to a method for encoding the borders of pixel regions of an image, wherein the borders contain a sequence of vertices subdividing the image into regions of pixels (superpixels), by generating a sequence of symbols from an alphabet including the step of: defining for each superpixel a first vertex for coding the borders of the superpixel according to a criterion common to all superpixels; defining for each superpixel the same coding order of the border vertices, either clockwise or counter-clockwise; defining the order for coding the superpixels on the base of a common rule depending on the relative positions of the first vertices; defining a set of vertices as a known border, wherein the following steps are performed for selecting a symbol of the alphabet, for encoding the borders of the superpixels: a) determining the first vertex of the next superpixel border individuated by the common criterion; b) determining the next vertex to be encoded on the basis of the coding direction; c) selecting a first symbol (“0”) for encoding the next vertex if the next vertex of a border pertains to the known border, d) selecting a symbol (“1”; “2”) different from the first symbol (“0”) if the next vertex is not in the known border; e) repeating steps b), c), d) and e) until all vertices of the superpixel border have been encoded; f) adding each vertex of the superpixel border that was not in the known border to the set; g) determining the next superpixel whose border is to be encoded according to the common rule, if any; i) repeating steps a)-g) until the borders of all the superpixels of the image have being added to the known border.
@patent{201809_grangetto_methods, title = {Methods and {Apparatuses} for {Encoding} and {Decoding} {Superpixel} {Borders}}, assignee = {Sisvel Technology S.r.l}, number = {WO2018158738 (A1)}, author = {Grangetto, Marco and Verdoja, Francesco}, month = sep, year = {2018}, } -
 Methods and Apparatuses for Encoding and Decoding Digital Images Through SuperpixelsGiulia Fracastoro, Enrico Magli, Francesco Verdoja, and Marco GrangettoMar 2017
Methods and Apparatuses for Encoding and Decoding Digital Images Through SuperpixelsGiulia Fracastoro, Enrico Magli, Francesco Verdoja, and Marco GrangettoMar 2017A method and an apparatus for encoding and/or decoding digital images or video streams are provided, wherein the encoding apparatus includes a processor configured for reading at least a portion of the image, segmenting the portion of the image in order to obtain groups of pixels identified by borders information and containing at least two pixels having one or more homogeneous characteristics, computing, for each group of pixels, a weight map on the basis of the borders information associated to the group of pixels, a graph transform matrix on the basis of the weight map, and transform coefficients on the basis of the graph transform matrix (U) and of the pixels contained in the group of pixels.
@patent{201703_fracastoro_methods, title = {Methods and {Apparatuses} for {Encoding} and {Decoding} {Digital} {Images} {Through} {Superpixels}}, assignee = {Sisvel Technology Srl; Politecnico Di Torino}, number = {WO2017051358 (A1)}, author = {Fracastoro, Giulia and Magli, Enrico and Verdoja, Francesco and Grangetto, Marco}, month = mar, year = {2017}, }